OSI 模型简介
前言
对于我们每天使用的互联网来说,你有没有想过,它的底层是如何被实现的?
你的打开手机浏览器,想要搜索点什么,有没有想过消息是如何传递搜索引擎,又是如何从它那边拿到了你想要的结果,抛开那些很复杂的逻辑背后,我们可以来讲一讲互联网的基石 —— 网络协议。
什么是网络协议
网络协议,也被成为传输协议,这里我们指的是,在任何物理介质中允许两个或多个在传输系统中的终端之间传播信息的系统标准,也是指计算机通信或网路设备的共同语言,举一个现实的例子,一名土生土长的亚马逊丛林部落人 (MachineA) 和一名阿拉伯人 (MachineB) 之间肯定无法直接交流,正常来说,直接加配一个翻译即可,但是对于计算机而言,使用第三方插件 (用翻译) 远远没有统一标准化来的方便 (两个人都学同一门语言),只要将这个 “语言” 规范化,每台终端设备都将其内置,万物互联的网络就诞生了。
协议的运用
不只是网络,其实生活方方面面我们也能看的协议的存在,例如 WIFI6 协议、USB3.2 协议等等,注意这些属于公共协议,背后有相应的联盟在制定标准更新,与之相对的还有私有协议,例如各大手机厂家的快充协议,如果不是使用原厂充电头,协议无法被匹配,就无法使用快充模式,在后面我们也可以自己来写一套简单的私有协议
协议遵循的规范
在了解具体的协议详情之前,我们需要抛开细节,来着重讲解一下现行互联网络的参考模型,这是一个很抽象的结构,你可以将其具象化为一个 Request (请求) 所需要经过的流程,例如地址栏输入 [baidu.com](http://baidu.com) 后敲击回车,你可以简单理解为向百度服务器发起了一次 Request,正确理解这些术语可以让我们后面写代码的时候不至于两眼一抹黑。
每一本讲解网络原理的书本上,第一章或者第二章肯定会是 OSI 七层模型,足以说明它的重要性和必要,开放式系统互联模型 (Open System Interconnection Model, OSI) 是由国际标准化组织 ISO 提出,ISO的成员由来自世界上100多个国家的国家标准化团体组成,代表中国参加 ISO 的国家机构是中国国家技术监督局(CSBTS),可以看看牛奶包装上,是不是必须要经过 ISO 认证才能上市,所以很好记 —— ISO 组织提出了 OSI 模型。
OSI 模型将通信系统中的数据流划分为七个层,从分布式应用程序数据的最高层表示到跨通信介质传输数据的物理实现。每个中间层为其上一层提供功能,其自身功能则由其下一层提供,功能的类别通过标准的通信协议在软件中实现。先快速过一遍一次请求中,所需要停留的每一层的作用:
首先我们会发起一个 WebRequest 给 Baidu Server (百度服务器) —— 应用层
Request 数据如果包含图片等内容,会被压缩打包 —— 表示层
计算机选择如何建立连接以及附属工作,例如是否需要优先传递这个 Request —— 会话层
计算机在你和 Server 之间寻找出一条最优路由 —— 网络层
数据被传入消息管道,可以抽象为 Client (客户端,就是你的电脑) 和 Server 之间有一条水管,Request 从 Client 流入且从 Server 流出 —— 传输层
通过 WIFI 等介质发送到路由器 —— 数据链路层
0101 的比特流在电缆光纤中传输 —— 物理层
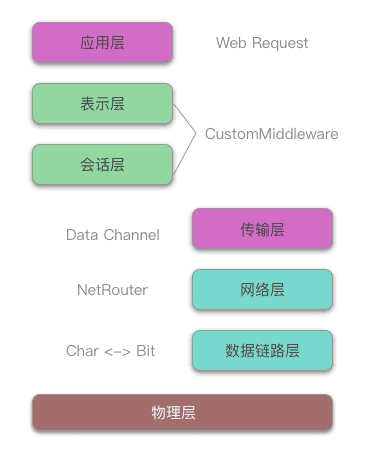
注意上面 Request 流程调换了网络层和传输层的位置(图没换) ,那是因为这个模型提出的时间是 20 世纪 70 年代,放到只能用于理论中,但是一些大家已经约定俗称 七层 —— 网络层、四层 —— 传输层 了,包括文档说明,所以自己能调换只为了帮助理解。
OSI 模型
现在用严谨学术的话再重新理解一遍 OSI 模型,下面图其实说明得就非常清晰
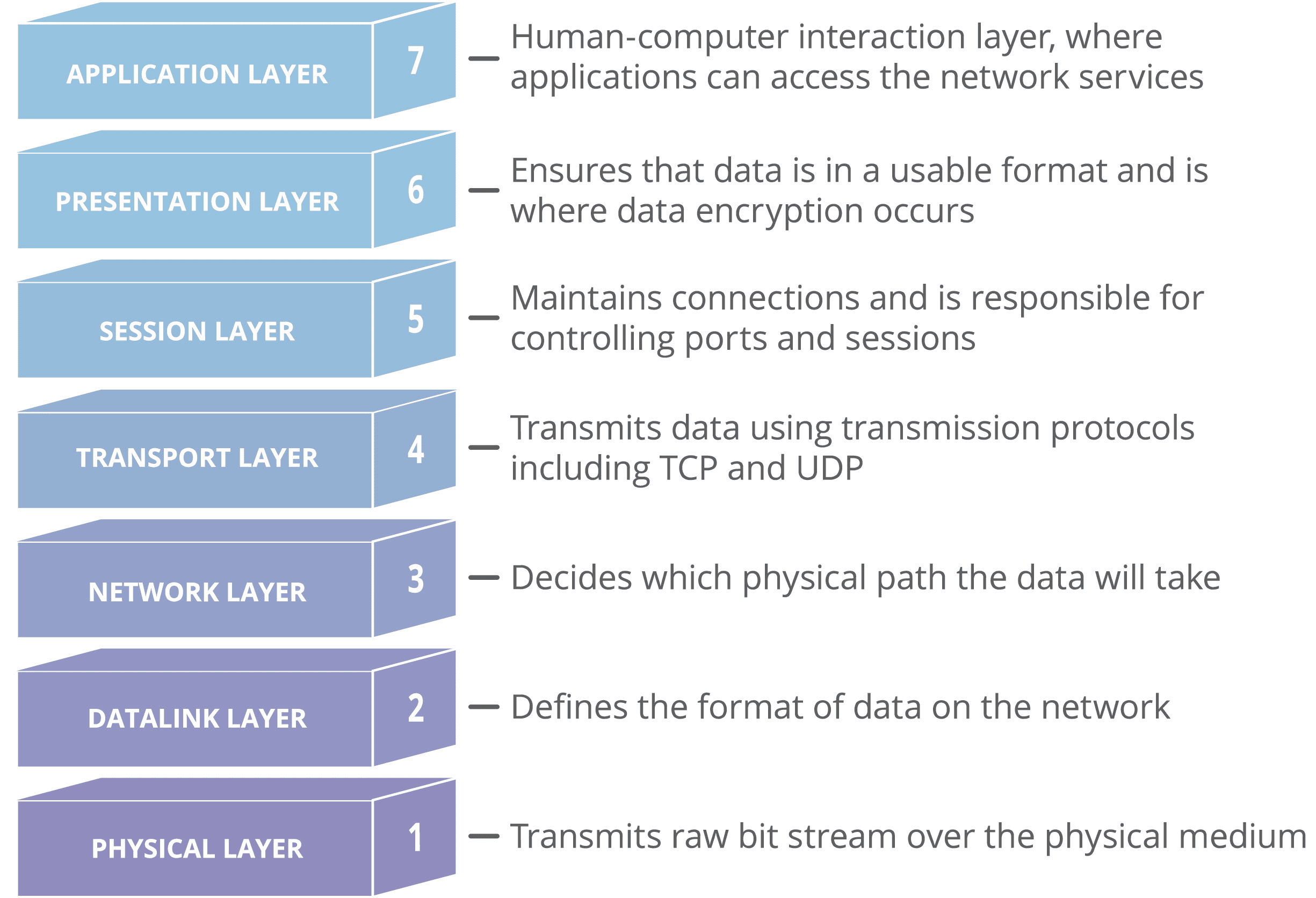
- 应用层:提供为应用软件而设计的接口,以设定与另一应用软件之间的通讯
- 表示层:把数据转换为能与接收者的系统格式兼容并适合传输的格式
- 会话层:也有翻译为会议层,负责在数据传输中设定和维护计算机网络中两台计算机之间的通讯连接
- 传输层:只有 TCP/UDP 两种通讯传输协议,把传输表头(TH)加至数据以形成数据包,传输表头包含了所使用的协定等传送数据
- 网络层:决定数据的路径选择和转寄,将网络表头(NH)加至数据包,以形成封包。网络表头包含了网络资料
- 数据链路层:负责网络寻址、错误侦测和改错。当表头和表尾被加至数据包时,会形成消息框(Data Frame)。数据链表头(DLH)包含了实体位址和错误侦测及改错的方法。数据链表尾(DLT)是一串指示数据包末端的字符串。同时它的底下又分为两个子层:逻辑链路控制(logical link control,LLC)子层和介质访问控制(Media access control,MAC)子层
- 物理层:在局部区域网络上传送数据帧(Data Frame),它负责管理电脑通讯设备和网络媒体之间的互通。包括了针脚、电压、线缆规范、集线器、中继器、网卡、主机介面卡等
通过实战来验证
编程当中有一个很重要的思想,就是 OOP 面向对象,里面有一个手段是我们需要掌握的,即封装,它将对象抽象成一个实体,隐藏了对象的属性和实现细节,也是举个例子,A班小明小红的身高、长相等等就是属于细节,但是我需要让这个班去操场搞卫生的时候,这些细节就被抽象为某个人,例如我可以说派 A 班某个人去拔草,是谁并不重要,我只需要一个一个实体,也就是我们之后会用到的 A班.Someone 这样去使用它。
忽略掉不必要的细节,将对象概括为一个实体,这个思想同样也可以用在学习网络模型中,我们在讲解每一层的某个协议的时候,并不会特意涉及到其他层的实现细节,例如发送了某个 “ABCD”,我并不会说如何发送的,因为这对于聚焦当前内容无足轻重。
应用层
HTTP协议
这个协议是一个很经典的七层协议 (应用层),其实相当地常见

看到那个 https 了吗,其实就是加了密的 HTTP 协议,你可以理解为 Client 和 Server 之间用遵循 HTTP 协议的语言在说话,你提出要访问某个网页 (HTTP Request),服务器正确理解了你的需求后给你发送了网页 (Response),这里可以试着抓一下 HTTP 报文,看看里面是怎么实现的
工具:
Charles —— Mac/Windows 平台下的 HTTP 抓包工具

https://www.charlesproxy.com/download/
抓包工具的配置
在使用抓包工具之前,我们需要安装一个 CA 证书,证书的作用就是抓到了 https 包之后,可以正确解密内容,否则我们只能看见乱码,注意平常不要安装来路不明的证书,否则你的通讯将会被别人劫持
这里以我常用的 Charles 为例,其他软件都大同小异,首先在 Help 里面找到 Install Charles Root Certificate
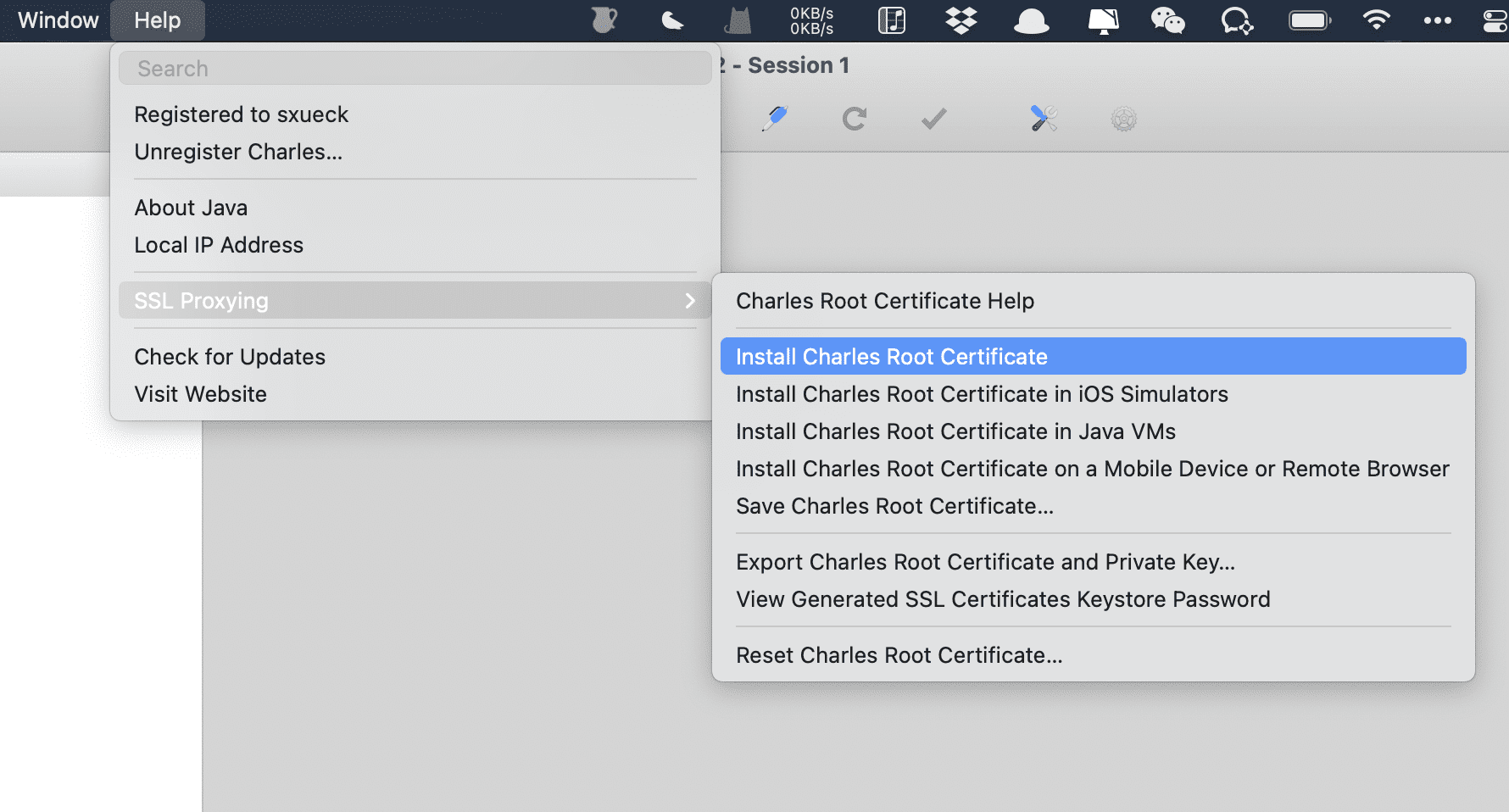
点击后在 钥匙串 的根证书处找到 Charles Proxy CA

双击进入,将其修改为始终信任

之后返回 Charles,找到 Proxy - SSL Proxying Settings
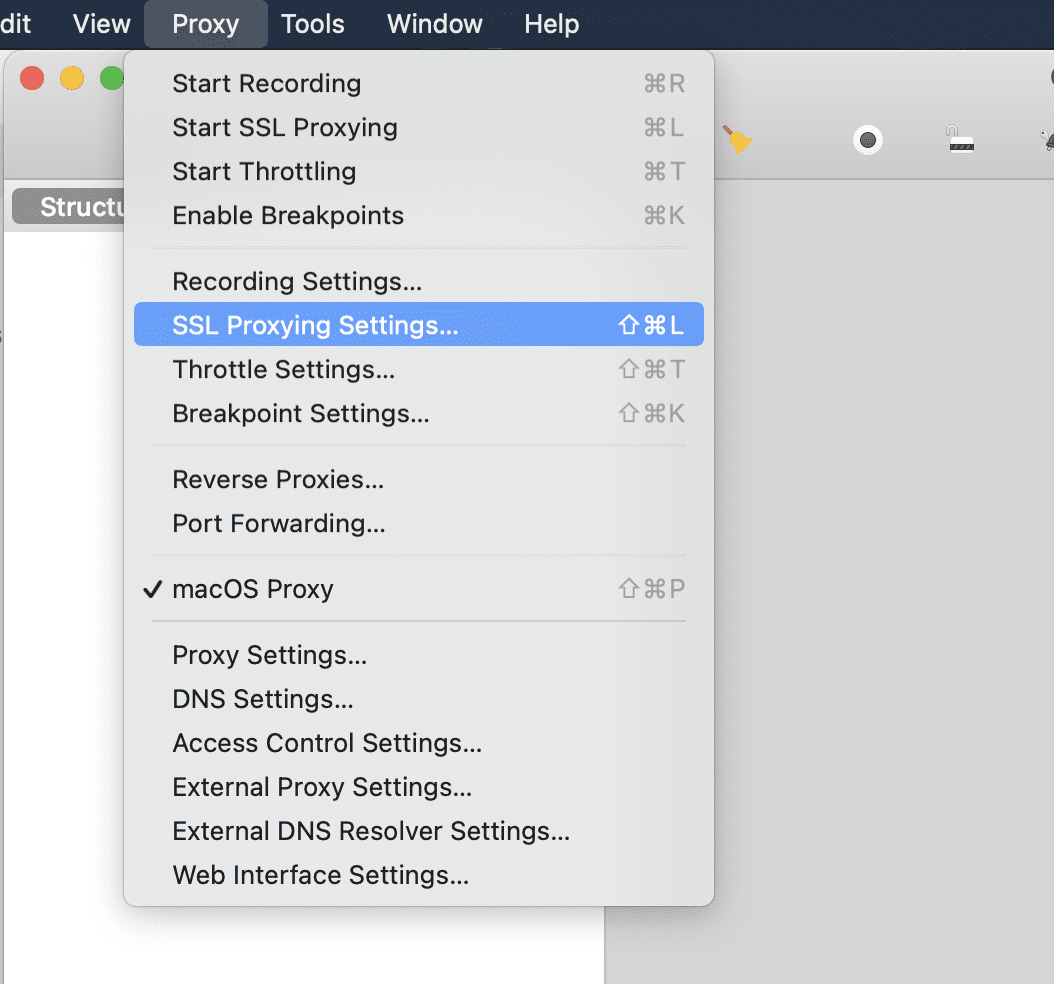
选择 Add,输入 *.* ,代表抓取所有的 https 网站,最后选择确认即可
验证
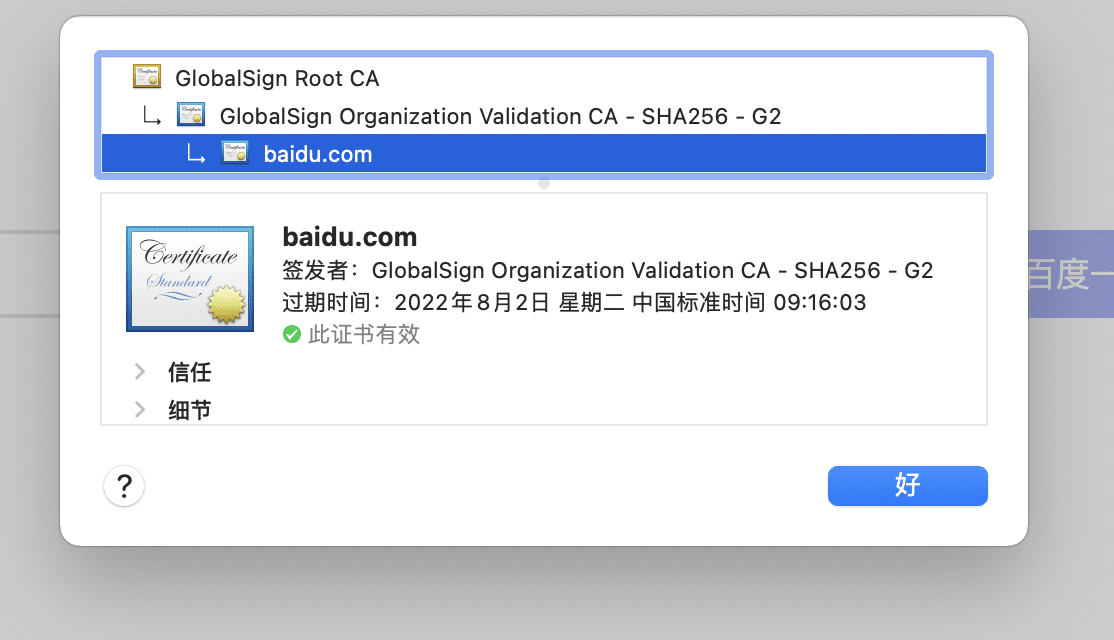
我们可以先将抓包软件关闭,然后使用 Chrome 浏览器 打开一个网页,点击地址栏旁边的锁,选择证书,可以看到没有开启抓包钱的签发者是 GlobalSign 组织
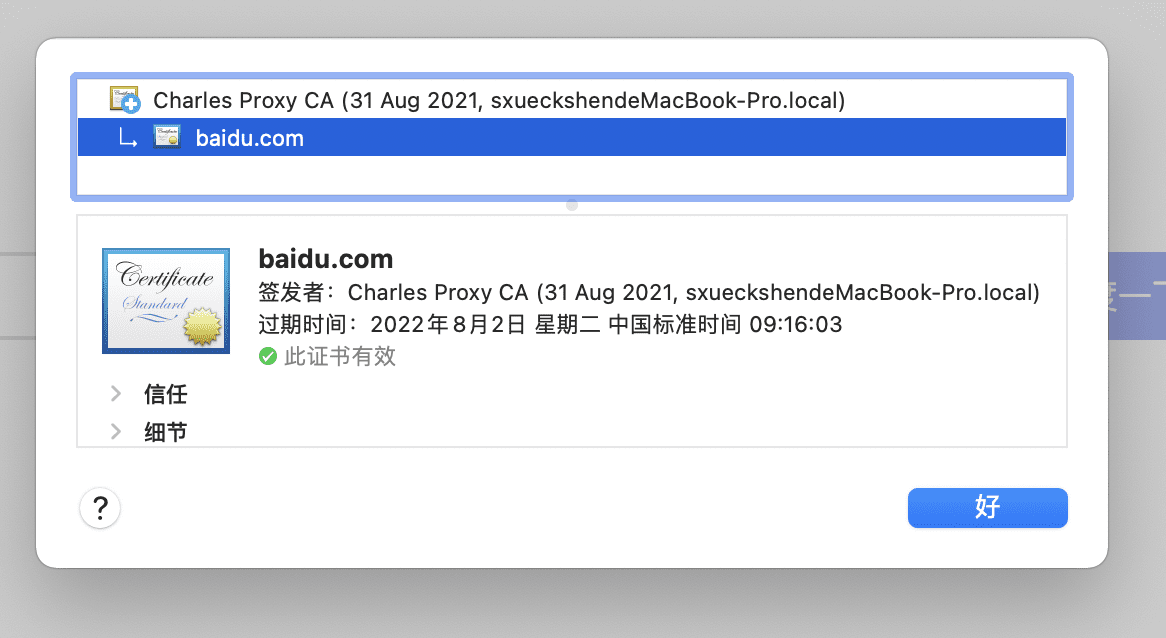
现在让我们打开抓包工具,如果你的配置是正确的,证书应该显示为我们自己签发信任
一个 HTTP 报文的说明
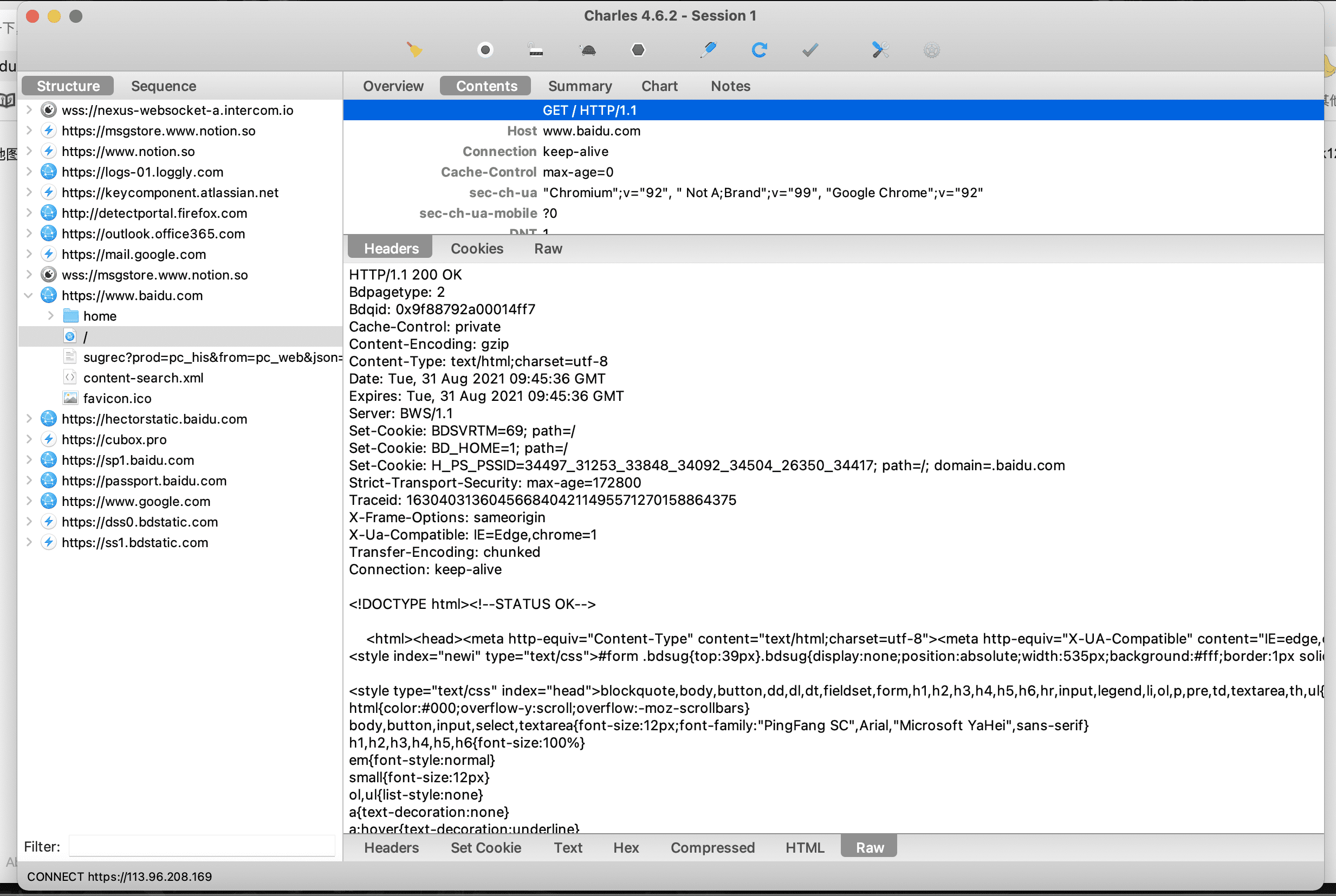
这里是一个访问百度的 HTTP Request (Overview 一栏) 和 Response 下面,意思是我发给百度的服务器上面一串规范化的报文,百度返回给下面的规范化的报文,这样就完成了我对百度首页的访问
Request 报文
GET / HTTP/1.1
Host: www.baidu.com
User-Agent: Mozilla/5.0) Chrome/92.0.4515.159 Safari/537.36
Accept: text/html,application/xhtml+xml
上面的一串英文就是最简化后的一个完整 Request 报文,只要有了这几样东西,我们就可以自己手动模拟出来,关于更具体的内容,可以在之后的 HTTP 协议篇专门进行深入学习
- Method:代表 HTTP 方法,可以把网页想象成一种资源,通过方法来实现我们想要的操作,例如这里是 GET 网页 (获取网页),另外还有 POST、DELETE (删除网页,如果服务器允许的话) 等等方法
- Host:目标主机
- User-Agent:用户的浏览器标识,服务器通过这个来鉴别来源访问是否为机器人,在爬虫篇中这个参数及其重要
- Accept:可选字段,代表用户浏览器可以接受的数据类型
只要按照规范填写了这几个字段,百度的服务器就会认为这是一次正确的请求,之后会将我们需要的资源,即 GET / 的这个 / 也就是根目录,如果我们使用 GET /index ,百度就要给我们 index 这个页面,当然有没有就另说了
Response 报文
在说明这个报文之前,有必要先了解几个概念
- 端口:狭义上的端口可以认为是计算机与外界通讯交流的出口,你可以理解为一栋房子的大门,如果你的计算机想与外界通讯的话,必须要开放一个端口 (大门) 给人家,一台计算机 (一栋房子) 最多只能有 65535 个端口 (大门),为了方便,我们通常会约定俗称一些端口为某个服务提供固定号码,例如 21 端口是 FTP 文件共享服务、80 端口是 Web HTTP 服务 (也就是平常访问的网站都是使用该端口的 ) 等等。一般来说,1024 以下的端口都不应该被个人使用,因此对这些端口进行绑定监听都需要系统管理员权限。
- 数据包:应用层中一次请求的叫法,例如对某台服务器发起了一次请求,我们可以抽象为中间有一个数据包被发过去了,因此拦截中间的通讯数据也被称之为抓包,一个数据包也就是报文,由 Header (报文头) 和 Body (报文正文) 两个部分组成。
了解之后,先来看看百度服务器的 ****Response 报文的内容
HTTP/1.1 200 OK
Cache-Control: private, no-cache, no-store, proxy-revalidate, no-transform
Connection: keep-alive
Content-Encoding: gzip
Content-Type: text/html
Date: Thu, 02 Sep 2021 03:09:08 GMT
Last-Modified: Mon, 13 Jun 2016 02:50:13 GMT
Pragma: no-cache
Server: bfe/1.0.8.18
......
</script>
<script src="https://dss0.bdstatic.com/5aV1bjqh_Q23odCf/static/superman/js/components/hotsearch-c445acece1.js"></script>
<script defer src="//hectorstatic.baidu.com/cd37ed75a9387c5b.js"></script>
</body>
</html>
上面中橙色部分就是 Header,由 Key: Value 的格式组成,下面就是 Body,是一段网页的源码,通过这样的形式,就可以将网页以源码的方式送达用户的浏览器上,并由浏览器进行渲染和加载
HTTP 模拟实战前置
在有了对于 HTTP 报文的一定了解后,我们可以通过一个简单的实战实验进行一个加深了解
不过在此之前,首先需要学习几个命令行工具的运用,这些命令行工具都是在 Linux 或者 MacOS 中的,不太推荐使用 Windows
什么是命令行工具
命令行工具,即 Cli (command-line interface)。是在图形用户界面得到普及之前使用最为广泛的用户界面,它通常不支持鼠标,用户通过键盘输入指令,计算机接收到指令后,予以执行,通常来说,调用一个命令行的格式为 工具本体名 -选项
下面例子中, rm 属于一种命令行工具, -rf 属于选项,通过选项来拓展我们想要的操作,每个命令都有不同的选项
rm someone # 删除某个文件
rm -rf somedir # 删除某个文件夹
netcat :一把瑞士军刀
netcat (通常缩写为nc) 是一种计算机联网实用程序,也是功能丰富的网络调试和调查工具,因为它可以产生用户可能需要的几乎任何类型的连接,并具有许多内置功能。因此被称为网络工具中的瑞士军刀,体积小巧,但功能强大。简单来说,它能模拟任何连接,在以后的学习中,处处都能看见它的身影。
打开终端,输入 nc 指令,如果没有提示 command not found ,就代表命令已经安装好了
~ nc
usage: nc [-46AacCDdEFhklMnOortUuvz] [-K tc] [-b boundif] [-i interval] [-p source_port]
[--apple-recv-anyif] [--apple-awdl-unres]
[--apple-boundif ifbound]
[--apple-no-cellular] [--apple-no-expensive]
[--apple-no-flowadv] [--apple-tcp-timeout conntimo]
[--apple-tcp-keepalive keepidle] [--apple-tcp-keepintvl keepintvl]
[--apple-tcp-keepcnt keepcnt] [--apple-tclass tclass]
[--tcp-adp-rtimo num_probes] [--apple-initcoproc-allow]
[--apple-tcp-adp-wtimo num_probes]
[--setsockopt-later] [--apple-no-connectx]
[--apple-delegate-pid pid] [--apple-delegate-uuid uuid]
[--apple-kao] [--apple-ext-bk-idle]
[--apple-netsvctype svc] [---apple-nowakefromsleep]
[--apple-notify-ack] [--apple-sockev]
[--apple-tos tos] [--apple-tos-cmsg]
[-s source_ip_address] [-w timeout] [-X proxy_version]
[-x proxy_address[:port]] [hostname] [port[s]]
curl : 命令行下的浏览器
curl 是一个利用 URL 规则在命令行下工作的文件传输工具,可以说是一款很强大的 http 命令行工具。它支持文件的上传和下载,是一种综合传输工具,在 curl 的眼里,一切的网页不过是一串串字符,所以了解较为底层的 HTTP 就靠它了,同样在往后的篇章里面,它也是会经常出现的一种工具。
手动模拟一个网站
前面说了,我们看见的网页,只不过是服务器返回了的源码经过浏览器渲染后的结果,无非就是 Headers + Body 组成的数据包而已,照着这个思路,我们可以试试用 nc 命令来模拟一个网页
伪造一个 Response 数据包最简单的方法就是直接拿一个现成的来修改,我们先使用 curl 拿到百度服务器给过来的 Headers,将其中的字段修改成我们自己的即可
$ curl -I baidu.com # -I 代表只显示 Headers,不显示 Body
HTTP/1.1 200 OK # 代表这是一次正常的访问
Date: Thu, 02 Sep 2021 05:55:23 GMT # 数据包的时间戳,给浏览器做校验,如果时间差太多浏览器就不认了,注意时区
Server: Apache # 网页服务的名称
Last-Modified: Tue, 12 Jan 2010 13:48:00 GMT # 页面的上次修改时间
ETag: "51-47cf7e6ee8400"
Accept-Ranges: bytes
Content-Length: 81 # 和上面的字段结合起来看,代表整个页面的大小,提醒浏览器接受到这里就可以结束了
Cache-Control: max-age=86400 # 页面在浏览器中缓存的时间,这个时间内,你都是直接从本地拿的这个页面
Expires: Fri, 03 Sep 2021 05:55:23 GMT
Connection: Keep-Alive
Content-Type: text/html # 网页的页面类型
抹去一些对我们无用的字段,再加上我们想要显示的网页源码,变成了下面这样
HTTP/1.1 200 OK
Date: Thu, 02 Sep 2021 06:14:12 GMT
Server: WoDeServer
Last-Modified: Tue, 12 Jan 2010 13:48:00 GMT
Cache-Control: max-age=86400
Expires: Fri, 03 Sep 2021 05:55:23 GMT
Content-Type: text/html
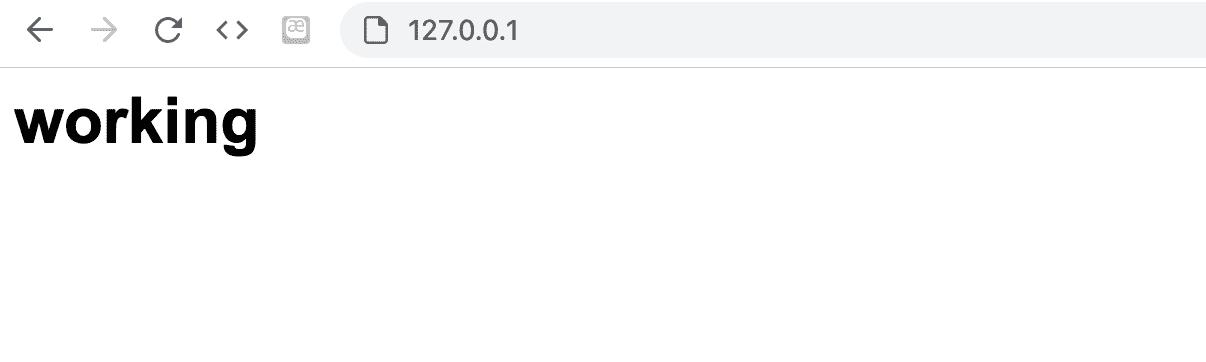
<h1>working</h1>
模拟开始,首先在终端输入下面的命令,意味着开启端口监听,承接外部的访问
nc -lvv 0.0.0.0 80
然后用浏览器访问 127.0.0.1 这个地址,你会看见浏览器一直处于加载中的状态,那是因为在等待服务器 (我们开启的 nc 命令) 回复,这时候马上切回到终端中,粘贴我们上面自己伪造的 Headers,之后按 Control + C / Ctrl + C 结束终端命令,能看到浏览器中已经有反应了