实验环境
- 操作系统:Debian 10
- Linux Kernel:5.10.x
前言
我在编写之前的文章《服务器性能优化之网络性能优化》中,其实有想把 BBR 作为一种优化手段写进去的,然而受限于篇幅不能过多讲解,因此特地单独细致地研究一遍。
通常我们在研究 BBR 算法的时候,会很难不将其与 Cublic 算法做比较,作为 Linux 内核默认的 TCP 拥塞控制算法,我们在这里也将会一并列入对比和实验中。
基本的概念
盖房先建地基,对应的学习一门知识也要先掌握与巩固前置基础,这里先将几个较为关键和频繁出现的知识要点来回顾一下,但在这里我将默认你已经掌握了基本的网络技术(例如滑动窗口,重传定时器等概念),否则你更需要的可能是一本网络入门书。
拥塞控制四板斧
由于 TCP 协议向应用层提供不定长的字节流发送方法,使得 TCP 协议先天性地有意愿去占满网络中的整个带宽,这时候当网络中许多连接同时试图去占满整个带宽的时候,就有可能发生恶性拥塞事件,因此 TCP 拥塞控制算法的作用,它能有效防止过多的数据注入到网络中,导致出现网络负载过大的情况。当 TCP 拥塞控制算法无法满足当前互联网应用对网络传输高实时性、高带宽利用率、高吞吐量的需求,在这种背景下 BBR 应运而生。
注意它和流量控制的区别,流量控制更多是作用于接收者,它控制发送者的发送速度从而使接收者来得及接收,防止数据分组丢失
在我们逐步分析对应控制手段之前,需要先行假设:
- 数据是单方向传递,另一个窗口只发送确认
- 接收方的缓存足够大,因此发送方的窗口大小由网络的拥塞程度来决定
慢启动
概念
我们都有过从互联网下载东西的经历,通常来说,文件的下载速率并不是一开始就达到到你的宽带上限,而是逐步从例如 1MB/s → 4MB/s 递增上去,这其实就是我们能看见的一种很典型的慢启动策略。
在这场下载中,发送方(即内容提供服务器)会维持一个叫做拥塞窗口 cwnd 的状态变量。它用来表示发送方在得到接收方确认前,最大允许传输的未经确认的窗口。拥塞窗口的大小取决于网络的拥塞程度,并且动态地在变化。
这时候我们又要引入两个新的词,即
- 通告窗口 rwnd
- 发送窗口 swnd = min(cwnd, rwnd)
虽然是新的词,但概念大体是新瓶装老酒,通告窗口就是我们 TCP 报文头的 Window 字段,也就是对方的接收窗口,例如我这里截了一张随手抓的报文内容,这里的 rwnd 就为 1021
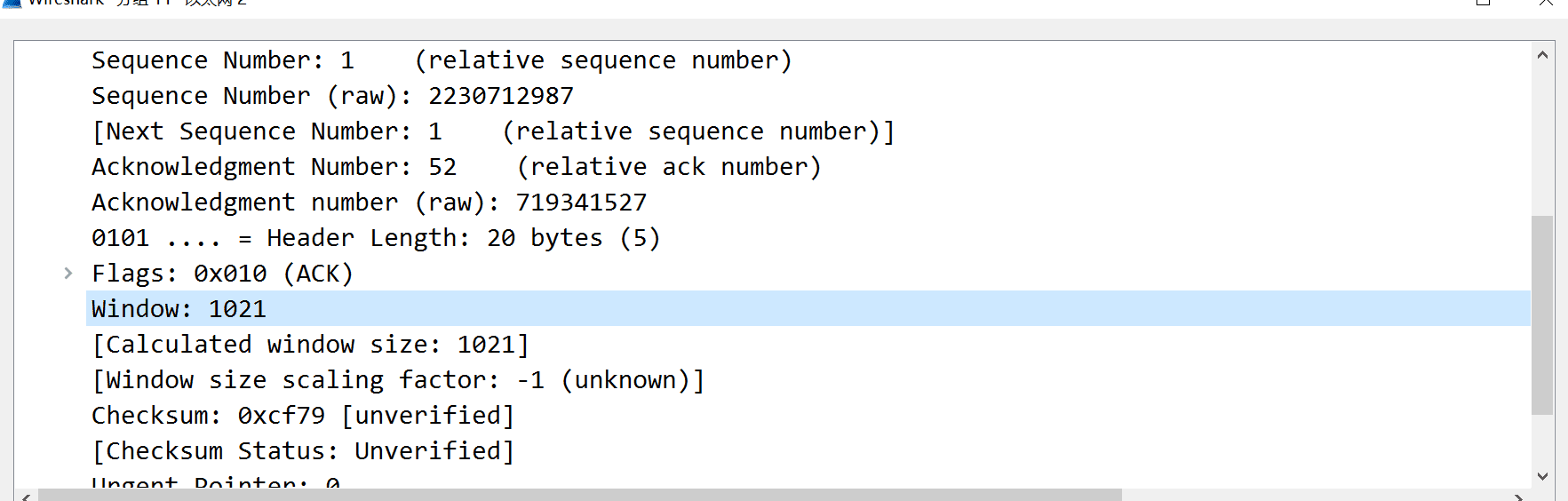
而发送窗口的概念就更简单了,它将 rwnd 与 cwnd 做比较,取两者最小值,如果我们将整条连接堪称一个水桶,那么它代表水桶中最短的那块木板,而 cwnd 与 rwnd 相比不同的是:它只是发送方的一个内部记数,无需通知给接收方,其初始值往往会比较小,然后随着报文被接收方确认,窗口成倍扩大,有点类似拳击比赛,开始时候不了解对方情况只能先行试探,后来心里有底了逐渐加大进攻力度。

在慢启动的过程中,随着 cwnd 的增加,可能会出现网络拥塞(因为大家都试探到了带宽上限),当开始出现丢包等故障情况,cwnd 的会立刻缩小,以便网络能够恢复正常。

拥塞避免
Appropriate Byte Counting
我们知道,TCP 发送端的数据发送速度受到本端拥塞窗口 cwnd 和对端通告的接收窗口 rwnd 的限制,只有同时在这两个窗口内的待发送数据才允许被发送到网络中。其中对端接收窗口是由对端接收缓冲区确定的,这里不考虑接收窗口的影响(视为接收窗口很大很大),而拥塞窗口的大小则是由不停的拥塞控制算法计算而来。
通常我们这样描述这两个阶段的窗口增加规则:慢启动阶段,每收到一个 ACK,拥塞窗口增加 1 个 MSS;拥塞避免阶段,每收到前一整窗的 ACK,窗口增加 1 个 MSS,换句话说,也就是说,每收到一个ACK,窗口增加 1/cwnd 个 MSS。
那么问题就来了,对于像 TELNET 或者 SSH 这类大部分情况下报文很短的 TCP 连接来说,当发送方收到 ACK (通常只应答几个 Bytes) 时,应该让发送方的拥塞窗口增加 1 个 MSS 或者 1/cwnd 个 MSS 吗?
这当然不太合理,一个例子是这种仅应答几个 Bytes 的 ACK 并不能反馈链路的拥塞情况:这些 ACK 可能将拥塞窗口撑得过大,而如果之后发送端真的发送拥塞窗口大小的数据,就有可能出现大量丢包。倘若 TCP 接收端采用了 delay-ACK ,将多个 TCP 报文放在一个 ACK 中应答,或者有一些 ACK 丢失了(ACK 不会重传),又会使得发送端拥塞窗口增加地较慢,影响 TCP 的传输性能。
所以问题的本质在于,发送端是根据收到 ACK 报文的数量来调整拥塞窗口,而不是根据 ACK 实际应答的数据长度来调整。
《RFC 3465 TCP Congestion Control with ABC》给出了一种更加恰当 (Appropriate)的以应答数据字节数 (Byte Counting) 为基础的窗口调整方案:
- 慢启动阶段:当 ACK 的数据长度达到 MSS 时,窗口增加 1 个 SMSS;
- 拥塞避免阶段:当 ACK 的数据长度达到整个拥塞窗口的大小时,窗口增加 1 个 SMSS。
这样,在 TCP 传输的报文是满 MSS 长度的报文时,是否使用 ABC 对拥塞窗口调整没有影响。
L = 2*SMSS
在RFC 3465 文档中,定义了一个变量 L, 它表示在慢启动阶段,收到 ACK 后拥塞窗口增加的最大值,其建议值为 2 倍 SMSS bytes,这一点严格来说是违反 RFC 5681 的(虽然标准被修正很正常),后者是这样描述的
We note that RFC3465 allows for cwnd increases of more than SMSS bytes for incoming acknowledgments during slow start on an experimental basis; however, such behavior is not allowed as part of the standard.
对此,RFC3465的理由是,选择 L=2*SMSS 是为了弥补 delayed-ACK 带来的多个性能影响
This document specifies that TCP implementations MAY use L=2SMSS bytes and MUST NOT use L > 2SMSS bytes. This choice balances between being conservative (L=1SMSS bytes) and being potentially very aggressive. In addition, L=2SMSS bytes exactly balances the negative impact of the delayed ACK algorithm
Linux 的实现
Linux 对 ABC 的实现分为三个时期:
显式 Sysctl 选项支持 ABC
以 Kernel 2.6.x 版本为例,我们借以追溯一下该功能的工作方式
sysctl_tcp_abc: Appropriate Byte Counting 的开关
0 -- 关闭 ABC
1 -- 开启 ABC, 在慢启动阶段收到 ACK 时,拥塞窗口最多增加 1 个 SMSS
2 -- 开启 ABC, 在慢启动阶段收到 ACK 时,拥塞窗口最多增加 2 个 SMSS
内核使用 tcp_sock -> bytes_acked 来记录 ACK 报文应答的数据长度,该字段在收到 ACK 报文时更新。
static int tcp_ack(struct sock* sk, struct sk_buff *skb, int flag)
{
...
if (sysctl_tcp_abc){
if (icsk->icsk_ca_state < TCP_CA_CWR)
tp->bytes_acked += ack - prior_snd_una;
else if (icsk->icsk_ca_state == TCP_CA_Loss)
tp->bytes_acked += min(ack - prior_snd_una, tp->mss_cache);
}
}
慢启动阶段时,当累积的 bytes_acked 不够一个 SMSS 时,便会直接返回,不更新拥塞窗口。否则才更新,具体增加 1 个 SMSS 还是 2 个 SMSS,取决于 sysctl_tcp_abc 的值以及是否累积应答的数据长度。
void tcp_slow_start(struct tcp_sock* tp)
{
int cnt;
if (sysctl_tcp_abc && tp->bytes_acked < tp->mss_cache)
return;
// code omitted
else
cnt = tp->snd_cwnd;
if (sysctl_tcp_abc > 1 && tp->bytes_acked >= 2*tp->mss_cache)
cnt <<= 1;
tp->bytes_acked = 0;
tp->snd_cwnd_cnt += cnt;
while(tp->snd_cwnd_cnt >= tp->snd_cwnd)
{
tp->snd_cwnd_cnt -= tp->snd_cwnd;
if (tp->snd_cwnd < tp->snd_cwnd_clamp)
tp->snd_cwnd++;
}
}
而在拥塞避免阶段,也有 ABC 专门的处理逻辑。
void tcp_reno_cong_avoid(struct sock* sk, u32 ack, u32 in_flight)
{
// code omitted...
if (tp->snd_cwnd <= tp->snd_ssthresh)
tcp_slow_start(tp);
else if (sysctl_tcp_abc){
if (tp->bytes_acked >= tp->snd_cwnd*tp->mss_cache){
tp->bytes_acked -= tp->snd_cwnd*tp->mss_cache;
if (tp->snd_cwnd < tp->snd_cwnd_clamp)
tp->snd_cwnd++;
}
}
else {
// code omitted...
}
}
当 ABC 引入内核时,sysctl_tcp_abc 的默认值是 1(开启), 不过,在后来的一个补丁中,将其修改为了 0 (关闭)
快速重传与快速恢复
当出现丢包时候,TCP 将重新执行慢启动,此时意味着我们的拥塞窗口大幅度下降(且发送数据也会大幅度下降),当丢包出现的场景并不是很严重的时候,我们可以采用快速重传与快速恢复这种手段。
失序报文段
由于 IP 可能出现丢包、重复或者乱序的情况,为了保证
实验环境的搭建
我们现在部署一套位于不稳定网络的服务器,为了保证能看出控制算法在其中的作用,服务器和本地带宽均为 500Mbps,多次多地区实验
配置服务器
生成测试文件
$ fallocate -l 5G swap
$ ls -alh
total 5.1G
drwx------ 5 root root 4.0K Mar 20 15:37 .
drwxr-xr-x 19 root root 4.0K Mar 11 15:27 ..
-rw-r--r-- 1 root root 5.0G Mar 20 15:37 swap
测试方法
因为 Linux Kernel 4.9 默认启用了 BBR 算法,我们需要将其改成 Cublic 算法
$ sysctl net.ipv4.tcp_available_congestion_control
net.ipv4.tcp_available_congestion_control = reno cubic bbr # 查看 Kernel 当前支持的算法
$ lsmod | grep bbr
tcp_bbr 20480 14 # 查看到 BBR 算法模块在 Kernel 的名字
现在我们使用 blacklist 命令屏蔽 BBR 模块使其不会自动装入,但是其他非屏蔽模块需要该模块的话,系统依然会装入。
要避免这个行为,可以让 modprobe 使用 install 命令,通过改变 /etc/modprobe.d/blacklist.conf 文件,模块直接返回导入失败,就可以屏蔽其模块,以及所有依赖的模块(仅作临时测试用,这里事先打了 Snapshot)
$ echo "install tcp_bbr /bin/false" | sudo tee -a /etc/modprobe.d/blacklist.conf
$ reboot
$ sysctl net.ipv4.tcp_available_congestion_control
net.ipv4.tcp_available_congestion_control = reno cubic # 重启后看见 BBR 模块已经被卸载了
先启动服务端
$ iperf3 -s -p 5001
-----------------------------------------------------------
Server listening on 5001
-----------------------------------------------------------
客户端启动测试线程
$ iperf3 -c 8.216.11.113 -P 1 -i 2 -p 5001
Connecting to host 8.216.11.113, port 5001
[ 5] local 192.168.20.129 port 36204 connected to 8.216.11.113 port 5001
[ ID] Interval Transfer Bitrate Retr Cwnd
[ 5] 0.00-2.00 sec 1.50 MBytes 6.30 Mbits/sec 0 49.9 KBytes
[ 5] 2.00-4.00 sec 1.23 MBytes 5.14 Mbits/sec 19 11.4 KBytes
[ 5] 4.00-6.00 sec 1.35 MBytes 5.65 Mbits/sec 22 9.98 KBytes
[ 5] 6.00-8.00 sec 1.35 MBytes 5.65 Mbits/sec 0 18.5 KBytes
[ 5] 8.00-10.00 sec 1.10 MBytes 4.62 Mbits/sec 20 14.3 KBytes
- - - - - - - - - - - - - - - - - - - - - - - - -
[ ID] Interval Transfer Bitrate Retr
[ 5] 0.00-10.00 sec 6.53 MBytes 5.47 Mbits/sec 61 sender
[ 5] 0.00-10.10 sec 6.19 MBytes 5.14 Mbits/sec receiver
iperf Done.
这是一个单并发 10 秒的流量记录,我们能看到在 Cublic 算法下,极限带宽大约为 6Mbits/s,此时我们再测试一下 UDP 下的丢包率
$ iperf3 -c 8.216.11.113 -p 5001 -b 100M -t 30
Accepted connection from 218.18.239.249, port 59053
[ 6] local 172.25.33.57 port 5001 connected to 218.18.239.249 port 53504
[ ID] Interval Transfer Bitrate Jitter Lost/Total Datagrams
[ 6] 0.00-1.00 sec 10.1 MBytes 85.1 Mbits/sec 0.228 ms 0/7288 (0%)
[ 6] 1.00-2.00 sec 4.17 MBytes 35.0 Mbits/sec 0.394 ms 5148/8144 (63%)
[ 6] 2.00-3.00 sec 81.3 KBytes 666 Kbits/sec 0.397 ms 7671/7728 (99%)
[ 6] 3.00-4.00 sec 78.4 KBytes 642 Kbits/sec 0.396 ms 7632/7687 (99%)
[ 6] 4.00-5.00 sec 88.4 KBytes 724 Kbits/sec 0.396 ms 10245/10307 (99%)
[ 6] 5.00-6.00 sec 82.7 KBytes 677 Kbits/sec 0.481 ms 7636/7694 (99%)
[ 6] 6.00-7.00 sec 81.3 KBytes 666 Kbits/sec 0.511 ms 7636/7693 (99%)
[ 6] 7.00-8.00 sec 107 KBytes 876 Kbits/sec 0.380 ms 10258/10333 (99%)
[ 6] 8.00-9.00 sec 77.0 KBytes 631 Kbits/sec 0.340 ms 7644/7698 (99%)
[ 6] 9.00-10.00 sec 72.7 KBytes 596 Kbits/sec 0.297 ms 7678/7729 (99%)
[ 6] 10.00-11.00 sec 91.2 KBytes 748 Kbits/sec 0.403 ms 10225/10289 (99%)
[ 6] 11.00-12.00 sec 71.3 KBytes 584 Kbits/sec 0.325 ms 7674/7724 (99%)
[ 6] 12.00-13.00 sec 87.0 KBytes 712 Kbits/sec 0.397 ms 7632/7693 (99%)
[ 6] 13.00-14.00 sec 97.0 KBytes 794 Kbits/sec 0.323 ms 10245/10313 (99%)
[ 6] 14.00-15.00 sec 87.0 KBytes 712 Kbits/sec 0.356 ms 7652/7713 (99%)
[ 6] 15.00-16.00 sec 62.7 KBytes 514 Kbits/sec 0.320 ms 7670/7714 (99%)
[ 6] 16.00-17.00 sec 107 KBytes 876 Kbits/sec 0.353 ms 10223/10298 (99%)
[ 6] 17.00-18.00 sec 82.7 KBytes 677 Kbits/sec 0.335 ms 7659/7717 (99%)
[ 6] 18.00-19.00 sec 85.5 KBytes 701 Kbits/sec 0.340 ms 7643/7703 (99%)
[ 6] 19.00-20.00 sec 92.7 KBytes 759 Kbits/sec 0.369 ms 10222/10287 (99%)
[ 6] 20.00-21.00 sec 81.3 KBytes 666 Kbits/sec 0.321 ms 7624/7681 (99%)
[ 6] 21.00-22.00 sec 82.7 KBytes 677 Kbits/sec 0.310 ms 7704/7762 (99%)
[ 6] 22.00-23.00 sec 92.7 KBytes 759 Kbits/sec 0.493 ms 10171/10236 (99%)
[ 6] 23.00-24.00 sec 79.8 KBytes 654 Kbits/sec 0.355 ms 7697/7753 (99%)
[ 6] 24.00-25.00 sec 75.6 KBytes 619 Kbits/sec 0.285 ms 7659/7712 (99%)
[ 6] 25.00-26.00 sec 91.2 KBytes 748 Kbits/sec 0.348 ms 10210/10274 (99%)
[ 6] 26.00-27.00 sec 69.9 KBytes 572 Kbits/sec 0.347 ms 7656/7705 (99%)
[ 6] 27.00-28.00 sec 68.4 KBytes 561 Kbits/sec 0.390 ms 7669/7717 (99%)
[ 6] 28.00-29.00 sec 97.0 KBytes 794 Kbits/sec 0.326 ms 10210/10278 (99%)
[ 6] 29.00-30.00 sec 75.6 KBytes 619 Kbits/sec 0.347 ms 7655/7708 (99%)
[ 6] 30.00-30.15 sec 0.00 Bytes 0.00 bits/sec 0.347 ms 0/0 (0%)
- - - - - - - - - - - - - - - - - - - - - - - - -
[ ID] Interval Transfer Bitrate Jitter Lost/Total Datagrams
[SUM] 0.0-30.2 sec 2474 datagrams received out-of-order
[ 6] 0.00-30.15 sec 16.6 MBytes 4.62 Mbits/sec 0.347 ms 242648/254578 (95%) receiver
与之相对的,我们可以启用 BBR 拥塞控制算法后进行相同测试
# 带宽测试
Connecting to host 8.216.11.113, port 5001
[ 5] local 192.168.20.129 port 39476 connected to 8.216.11.113 port 5001
[ ID] Interval Transfer Bitrate Retr Cwnd
[ 5] 0.00-2.00 sec 1.85 MBytes 7.77 Mbits/sec 0 125 KBytes
[ 5] 2.00-4.00 sec 1.23 MBytes 7.14 Mbits/sec 0 125 KBytes
[ 5] 4.00-6.00 sec 1.26 MBytes 6.27 Mbits/sec 0 125 KBytes
[ 5] 6.00-8.00 sec 1.23 MBytes 7.14 Mbits/sec 0 125 KBytes
[ 5] 8.00-10.00 sec 1004 KBytes 8.11 Mbits/sec 0 125 KBytes
- - - - - - - - - - - - - - - - - - - - - - - - -
[ ID] Interval Transfer Bitrate Retr
[ 5] 0.00-10.00 sec 7.54 MBytes 7.48 Mbits/sec 0 sender
[ 5] 0.00-10.09 sec 5.91 MBytes 6.91 Mbits/sec receiver
# 丢包测试
Accepted connection from 218.18.239.249, port 56581
[ 5] local 172.25.33.57 port 5001 connected to 218.18.239.249 port 52661
[ ID] Interval Transfer Bitrate Jitter Lost/Total Datagrams
[ 5] 0.00-1.00 sec 10.3 MBytes 86.2 Mbits/sec 0.115 ms 0/7383 (0%)
[ 5] 1.00-2.00 sec 4.06 MBytes 34.1 Mbits/sec 0.342 ms 8048/8058 (99%)
[ 5] 2.00-3.00 sec 77.0 KBytes 631 Kbits/sec 0.362 ms 7654/7708 (99%)
[ 5] 3.00-4.00 sec 123 KBytes 1.00 Mbits/sec 0.337 ms 7671/7757 (99%)
[ 5] 4.00-5.00 sec 115 KBytes 946 Kbits/sec 0.313 ms 10223/10304 (99%)
[ 5] 5.00-6.00 sec 113 KBytes 923 Kbits/sec 0.278 ms 7671/7750 (99%)
[ 5] 6.00-7.00 sec 147 KBytes 1.20 Mbits/sec 0.256 ms 7608/7711 (99%)
[ 5] 7.00-8.00 sec 110 KBytes 900 Kbits/sec 0.748 ms 10185/10262 (99%)
[ 5] 8.00-9.00 sec 84.1 KBytes 689 Kbits/sec 0.353 ms 7739/7739 (100%)
[ 5] 9.00-10.00 sec 91.2 KBytes 747 Kbits/sec 0.313 ms 7653/7717 (99%)
[ 5] 10.00-11.00 sec 104 KBytes 853 Kbits/sec 0.341 ms 10184/10257 (99%)
[ 5] 11.00-12.00 sec 79.8 KBytes 654 Kbits/sec 0.272 ms 7666/7722 (99%)
[ 5] 12.00-13.00 sec 91.2 KBytes 747 Kbits/sec 0.277 ms 7654/7718 (99%)
[ 5] 13.00-14.00 sec 99.8 KBytes 818 Kbits/sec 0.419 ms 10202/10272 (99%)
[ 5] 14.00-15.00 sec 87.0 KBytes 712 Kbits/sec 0.397 ms 7630/7691 (99%)
[ 5] 15.00-16.00 sec 81.3 KBytes 666 Kbits/sec 0.252 ms 7672/7729 (99%)
[ 5] 16.00-17.00 sec 99.8 KBytes 818 Kbits/sec 0.437 ms 10191/10261 (99%)
[ 5] 17.00-18.00 sec 82.7 KBytes 677 Kbits/sec 0.275 ms 7651/7709 (99%)
[ 5] 18.00-19.00 sec 78.4 KBytes 642 Kbits/sec 0.266 ms 7671/7726 (99%)
[ 5] 19.00-20.00 sec 111 KBytes 911 Kbits/sec 0.372 ms 10178/10256 (99%)
[ 5] 20.00-21.00 sec 85.5 KBytes 701 Kbits/sec 0.265 ms 7631/7691 (99%)
[ 5] 21.00-22.00 sec 95.5 KBytes 783 Kbits/sec 0.318 ms 7685/7752 (99%)
[ 5] 22.00-23.00 sec 117 KBytes 958 Kbits/sec 0.284 ms 10195/10277 (99%)
[ 5] 23.00-24.00 sec 87.0 KBytes 712 Kbits/sec 0.398 ms 7646/7707 (99%)
[ 5] 24.00-25.00 sec 121 KBytes 993 Kbits/sec 0.370 ms 7646/7731 (99%)
[ 5] 25.00-26.00 sec 185 KBytes 1.52 Mbits/sec 0.224 ms 10131/10261 (99%)
[ 5] 26.00-27.00 sec 95.5 KBytes 783 Kbits/sec 0.250 ms 7655/7722 (99%)
[ 5] 27.00-28.00 sec 85.5 KBytes 701 Kbits/sec 0.218 ms 7627/7687 (99%)
[ 5] 28.00-29.00 sec 117 KBytes 958 Kbits/sec 0.321 ms 10220/10302 (99%)
[ 5] 29.00-30.00 sec 97.0 KBytes 794 Kbits/sec 0.239 ms 7655/7723 (99%)
[ 5] 30.00-30.14 sec 0.00 Bytes 0.00 bits/sec 0.239 ms 0/0 (0%)
- - - - - - - - - - - - - - - - - - - - - - - - -
[ ID] Interval Transfer Bitrate Jitter Lost/Total Datagrams
[SUM] 0.0-30.1 sec 72 datagrams received out-of-order
[ 5] 0.00-30.14 sec 17.1 MBytes 4.77 Mbits/sec 0.239 ms 242276/254583 (99%) receiver
对比下来,BBR 算法较通用了很久的默认 Cublic 算法有了一定程度的提升,主要表现在带宽占用率更高,以及丢包率有了小幅度降低(95%->99%)
结果
TCP算法存在的问题
典型拥塞控制算法思路
在互联网发展的过程当中,TCP 算法也做出了一定改变,先后演进了 Reno、NewReno、Cubic 和 Vegas,这些改进算法大体可以分为基于丢包和基于延时的拥塞控制算法。 基于丢包的拥塞控制算法以 Reno、NewReno 为代表,这类基于 AIMD 的算法只要未检测到丢包,均是无条件 AI(加性增窗)的,如此一来拥塞窗口总会超过实际宽带的限制。
理想情况下,如果我们把网络看作是一根粗细均匀管道,那么带宽就是该管道的横截面积,它一方面表示主机的发包能力,另一方面也表示网络的吞吐率。如果网络带宽被一条 TCP流独占,那么 Reno 的拥塞窗口理论上会无限 AI 涨下去,不会出现锯齿,而是一条直线。
很明显 Reno 并不理解宽带的概念,它只知道拥塞窗口。这里假如同一个网络管道中又出现一条 TCP 流,那么二者势必要分享带宽。需要分享出让带宽的信号就是拥塞丢包,按照 AIMD 窗口控制理论,当发生拥塞时,二者均会丢包,二者均要执行 MD(乘性减窗),然而如果第一个 TCP 流的窗口已经增长的过大,即便它执行了 MD,也依然远大于实际可用带宽,拥塞将持续,丢包将加剧。
因此,拥塞窗口必须维持在刚刚够用的状态,如果英语好的话,强烈推荐这里芝加哥洛约拉大学关于 NewReno 的讲解,在 Linux Kernel 2.6.13 以前的 Reno 算法中,拥塞窗口甚至就是无限增长。
我们需要重新加强认识一点,即拥塞控制的目标之一就是探测瓶颈带宽,控制主机发包速率使流量恰好通过瓶颈带宽。理想单流假设的前提下,主机的发包能力决定了拥塞窗口的上限,这个过程无需任何外在干预,单流完全可以自适应网络带宽,Reno 算法只是单纯的将拥塞窗口慢启动或者 AI 到 BDP 而已(在此我们忽略随机噪声丢包),理想单流的情况,网络就是一条单纯的管道,并不需要 Buffer。
然而如果多条流复用同一个网络,网络管道必然会过载,此时需要需要引入部署在交换节点 Buffer 来暂存过载的数据包,如果没有 Buffer,网络将退化到 CSMA/CD 总线,丢弃所有过载的数据包。
论 AIMD 如何保证对流公平
假设一种初始状态,一共 N 条流复用同一个网络,它们在网络过载的时刻拥塞窗口分别为 $$W_1, W_2, W_3,…W_N$$
而整个网络可容纳的数据包量为 W,即 W 为单流独享网络时的最大拥塞窗口,此时有:
$$W=W_1+W_2+W_3+…W_N$$
随即它们均感知到了丢包,它们均执行 MD,我们跟踪第一条流的窗口值变化,其它的流与此一致。
发生了 MD 之后,第一条流的窗口变为 $$\dfrac{W_1}{2}$$,此外,如前所述,如果交换节点发生拥塞,那肯定是针对所有流的,即所有流都会感知到拥塞,都会丢包,都会执行 MD 下降一半的窗口以排空网络,所以说此时网络的总空闲窗口变为为 $$\dfrac{W}{2}$$,接下来大家执行 AI,均分这么多的空闲窗口,即每个流增加窗口值 $$\dfrac{\frac{W}{2}}{N}$$
第一条流在接下来感知到丢包时的窗口分别为:
第2次感知到丢包: $$ W_{t1_1}=\dfrac{W_1}{2}+\dfrac{W}{2\times N}$$
第3次感知到丢包: $$W_{t1_2}=\dfrac{W_{t1_1}}{2}+\dfrac{W}{2\times N}$$
第4次感知到丢包: $$W_{t1_3}=\dfrac{W_{t1_2}}{2}+\dfrac{W}{2\times N}$$
…
第 i i+1 i+1 次感知到丢包: $$W_{t1_i}=\dfrac{W_{t1_{(i-1)}}}{2}+\dfrac{W}{2\times N}$$
将上面的式子整理,递推式子分别带入,这其实就是一个等差数列,最终初始窗口 W1 的作用削减到无所谓
$$W_1\_final=\dfrac{W_1}{2^{j+1}} + \dfrac{W}{2^{j+1} \times N} + \dfrac{W}{2^j \times N} + \dfrac{W}{2^{j-1} \times N} + … + \dfrac{W}{2 \times N}$$
忽略掉无穷小的量 $$\dfrac{W_1}{2^{j+1}}$$
此时约等于: $$\dfrac{W}{N}$$
如此,当我们有 N 条流,每一条流分得 W/N 的带宽,这就是 AIMD 的公平算法。
BufferBloat
学习现有的经典算法是非常有意义的事情,通过分析它们的优点和缺陷,触类旁通能对新的算法有更好更深的理解,这里 Buffer 出现的成因其实说明得非常明白了
TCP Queue Sizes suggested that an optimum backbone-router buffer size for TCP Reno might be hundreds of megabytes. Because RAM is cheap, and because more space is hard to say no to, queue sizes in the real world often tend to be at the larger end of the scale.
BufferBloat 很大的成因在于 Reno 家族(包括 BIC/CUBIC)的 CC 算法看待网络的方式。 Reno 的本质问题在于它将网络看成了一个容器而忽略了带宽。 我们可以从 Reno 家族的拥塞控制变量 cwnd 中看出来,cwnd 的单位是数据包的个数,而带宽的单位则是单位时间内的数据包的个数。这里可以看出,Reno 家族是 Buffer 友好的,却不是带宽友好的。
BBR正好与此相反,我们看到BBR的拥塞控制变量 Pacing Rate 的单位就是带宽的单位。因此 BBR 是带宽友好的,却不是 Buffer 友好的。现在让我们想象一个理想的 BBR 算法实现,并且整个网络均使用这个 BBR 实现进行拥塞控制。在这种情况下,路由器的 Buffer 将不再有大用,因为 BBR 总是可以通过不断测量瓶颈带宽和最小RTT(任何排队都会让RTT增加),最终收敛到所有的流均不在 Buffer 中排队。如果整个网络均切换到 BBR 进行拥塞控制,这势必会促使路由器厂商逐渐放弃将 Buffer 大小作为重要性能指标的策略,从而缓解整个网络的 BufferBloat
这里可以稍微引申一下 BBR 的内容了,现实中往往都是 BBR 与 Reno 共存状态,我们可以设想一个拥有无穷大的 Buffer 的网络,Reno 和 BBR 共享该网络的资源,此时 Reno 会倾向尽可能占满更多的 Buffer,这个行为会导致队列不断变长,测量得到的 RTT 不断增加,这会将 BBR 不断逼入 Probe RTT 阶段的超慢速传输。虽然现实网络中不可能拥有无穷大的 Buffer,但可以确定的是,即便是有限的 Buffer,由于空闲 Buffer 耗尽丢包导致的 Reno 进行 MD 以及重传行为也仅仅是缓解了上述 BBR 的窘境,而并非解决了该问题。
BBR算法的特点及核心
我在查资料的时候,正好看见 Virginia Tech(弗吉尼亚理工大学)有一则公开 PPT,里面就非常详细得阐述了关于 BBR 的 Challenges、Analysis 与 Solutions。有一个章节叫《TCP BBR: designed for maximum throughput, minimum latency》,就简单将我们上面罗里吧嗦一堆概念说的很明白:
Loss-based congestion control fills buffer, Achieves full throughput, but induces queuing delay
基于丢包的拥塞控制会使用到缓冲区,如果要实现高吞吐量必然会导致排队延迟
TCP BBR doesn’t fill buffer, Estimates bottleneck bandwidth and sends at that rate
TCP BBR 并不会占用到缓冲区(或者很少),更多是基于带宽速率进行判断
TCP BBR operates at the BDP, Also tries to estimate what link RTT is without queueing delay BDP = Bottleneck bandwidth x link RTT without queueing
TCP BBR 基于 BDP 运行,同时会估算无排队延迟下队列 RTT 长度,同时一个公式 BDP = 瓶颈带宽 x 无排队的链路 RTT
BBR 算法的核心是找到最大带宽(Max BW)和最小延时(Min RTT)这两个参数,最大带宽和最小延时的乘积可以得到 BDP (Bandwidth Delay Product), 而 BDP 就是网络链路中可以存放数据的最大容量。BDP 驱动 Probing State Machine(探测状态机)得到 Rate quantum 和 cwnd,分别设置到发送引擎中就可以解决发送速度和数据量的问题。
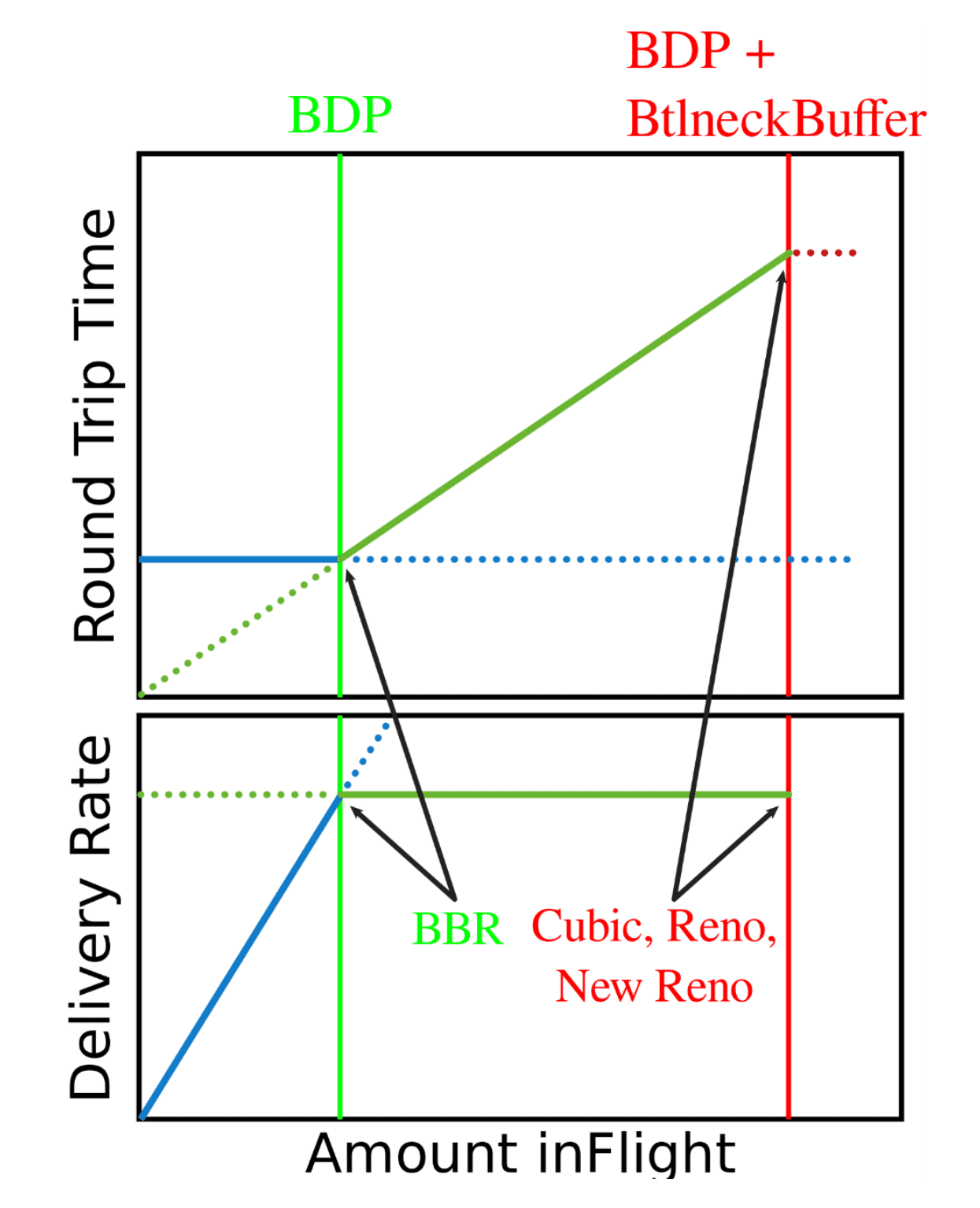
可以看出,在无排队的情况下,BBR 会优先吃满 BDP 带宽,在理想情况下,所有 TCP 拥塞控制算法的表现都差不多。
BBR算法的基本原理
BBR算法的优缺点
会导致BBR崩溃的几个点
抖动
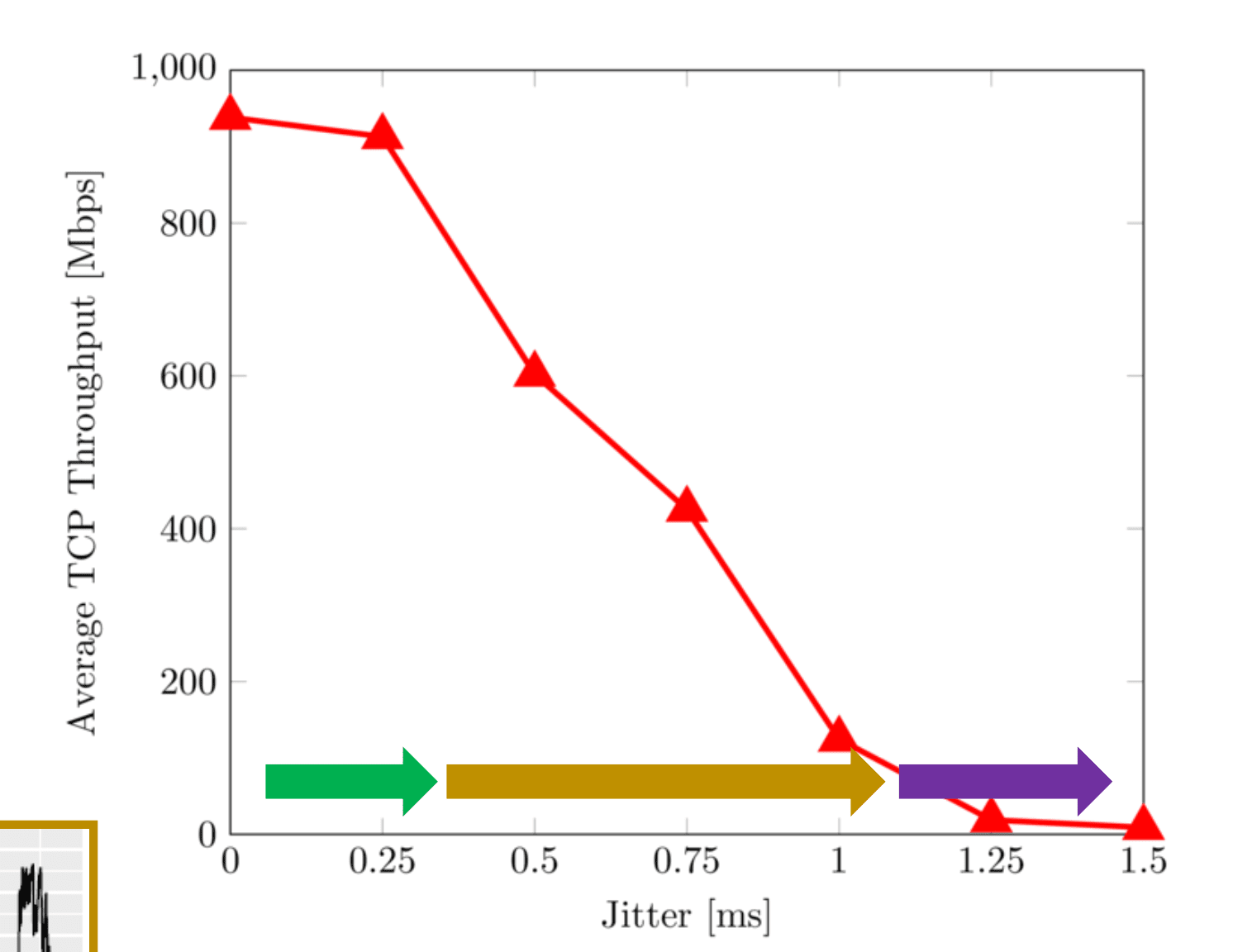
CWND耗尽
BBR劣势
起初抖动的增加并不会影响吞吐量,然而随着 TCP Throughput 的不断拉长,达到 1.5ms 的时候,线路将出现 “崩溃” 的迹象,这是因为当 RTT CWND < BDP
BBR算法的改进思路和方向
TCP拥塞控制算法已经持续发展了 30 多年,主流的拥塞控制算法是基于丢包的,即它们将数据包丢失作为拥塞信号。例如 Cubic 在遇到数据包丢失时将其拥塞窗口降低了30%。
但是,在某些情况下,基于丢包的 TCP 算法效果不佳。例如,在浅缓冲区中,数据包丢失可能被误解为网络拥塞,从而导致吞吐量降低和网络利用率降低。另一方面,在较深的缓冲区中,数据包通常要花很长时间才能填满缓冲区。这将导致较高的网络延迟,即缓冲膨胀问题。
如果我们客观看待 BBR 的几个特性,就会意识到:
- 瓶颈缓冲区大小和 BDP 之间的差异通常指示 BBR 何时运行良好。在较大的 BDP 和较浅的缓冲区大小下,BBR 可获得更高的吞吐量。
- 与 Cubic 相比,BBR 可能导致数倍的数据包重传。
- BBR 和 Cubic 之间的不公平性取决于瓶颈缓冲区的大小—如果缓冲区大小较小(10KB),则 BBR 可以获取总带宽的 90% 以上;具有较大的缓冲区大小(10MB),Cubic 可获得大约 80% 的总带宽。
根据 TCP Small Queues Question 内核草案,我们可以调整
/proc/sys/net/ipv4/tcp_limit_output_bytes以实现队列长度,队列补丁看起来至少能够填补这一空白。它限制了任何给定的 Socket 可以排队传输的数据量,而不管数据在哪里排队。缺省值为 128KB 。
通过决策树分析
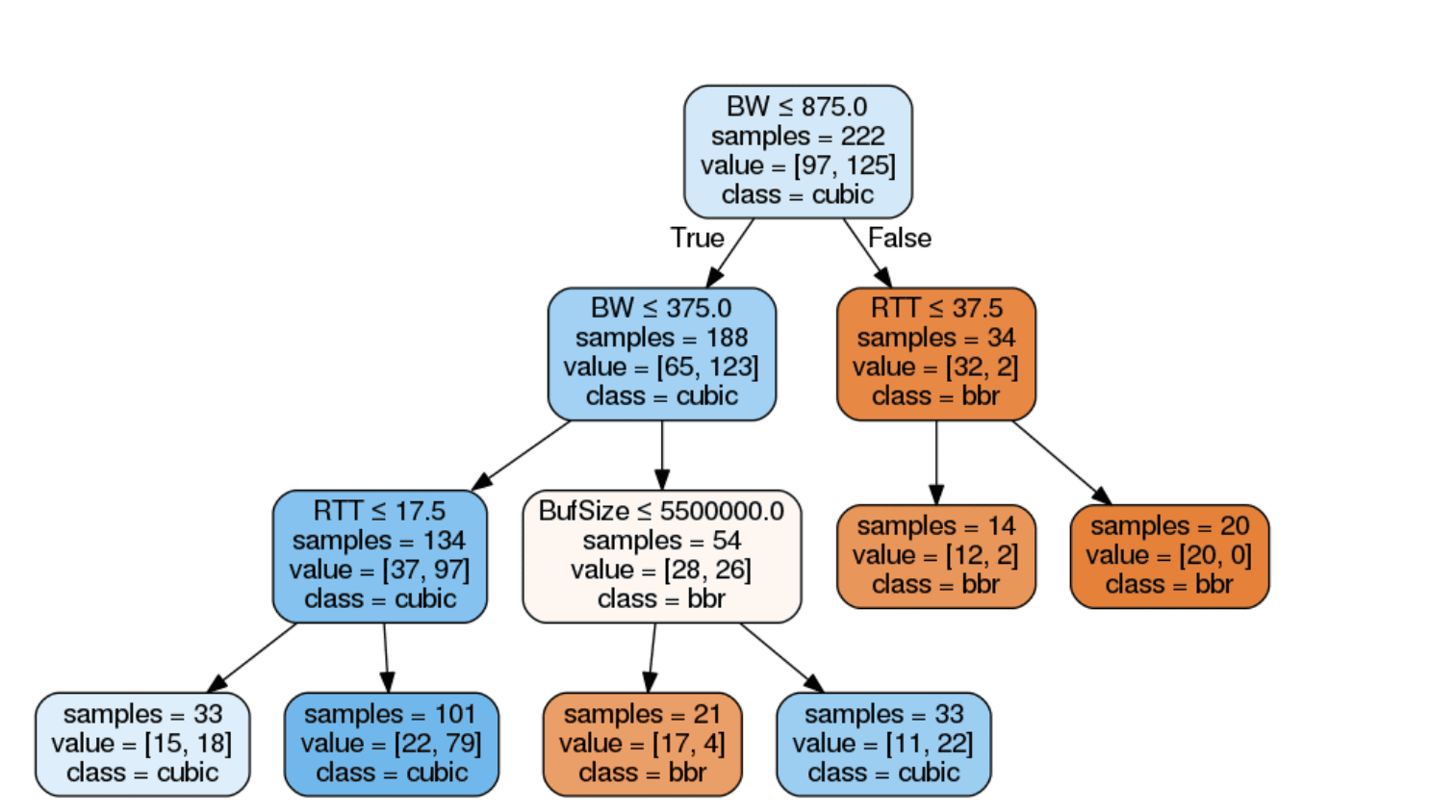
如果我们使用 iperf3 重复进行实验,再加以上面的图进行分析,不难看出在决策树中,橙色节点表示 BBR 获得更高吞吐量的实例,而蓝色节点代表 Cubic 获得更高吞吐量的实例。图中可以观察到,瓶颈缓冲区大小和 BDP 之间的相对差异通常决定了 BBR 何时运行良好,它表明在较小的 BDP 和较深的缓冲区大小下,Cubic 可获得较高的吞吐量,而在较大的 BDP 和较浅的缓冲区大小下,BBR 可获得较高的吞吐量。更高的产量。
也就是 BBR 与 BDP 呈现正相关,与缓冲区大小呈现负相关,而 Cubic 恰恰相反。
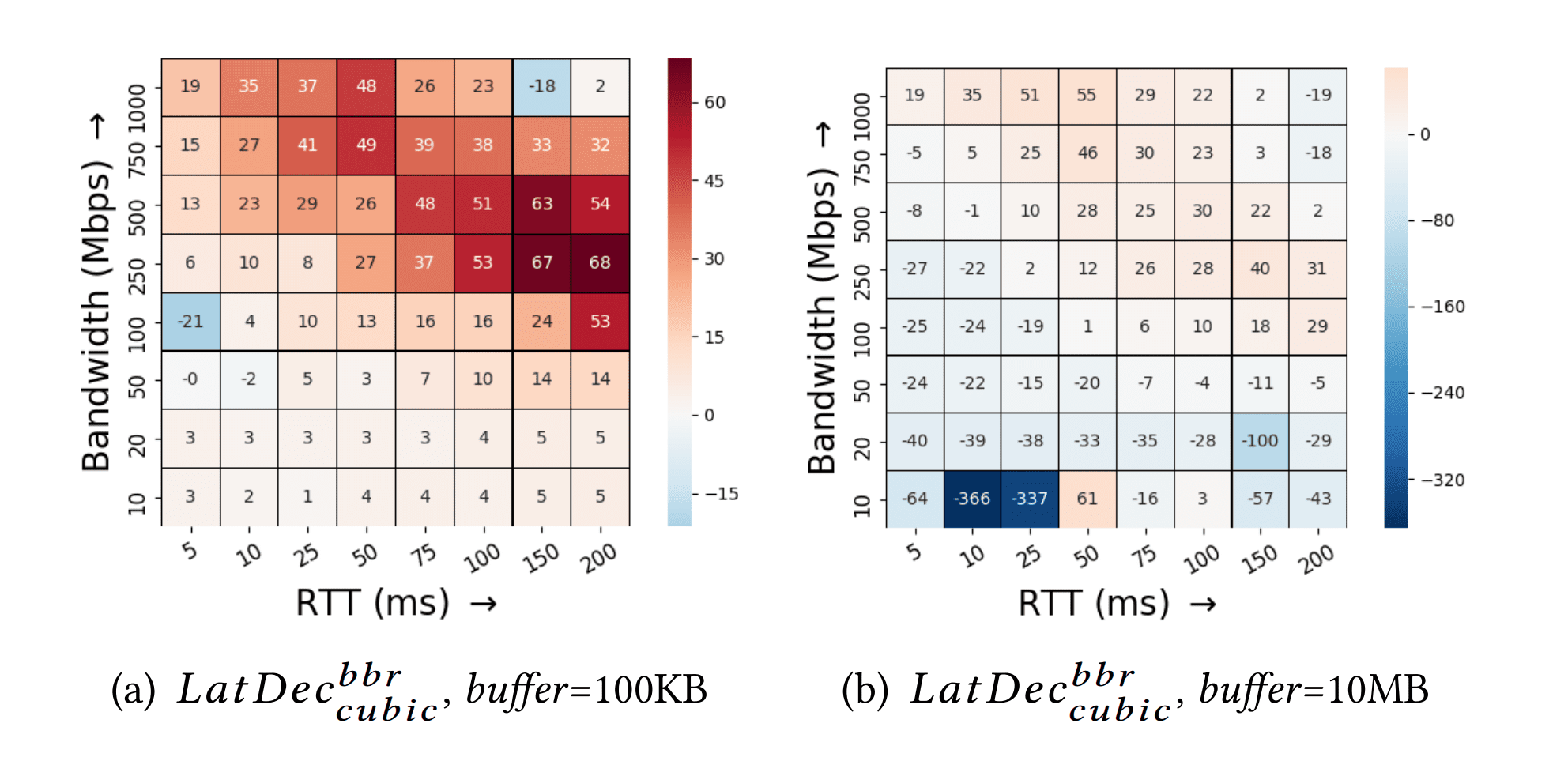
而为了分析和量化 BBR 与浅缓冲区中的 Cubic 相比,吞吐量的实际提高,我们可以定义一个以下指标:
$$ GpGain^{bbr}_{cublic} = \dfrac{goodput|BBR - goodput|Cublic}{goodput |Cubic} * 100 $$
这里绘制了两张热图,两边的方向轴分别为 RTT 和 Bandwidth,可以确切观察到到 BBR 与 Cubic 相比有显着改善(但是 10MB 缓冲区情况下,由于 Cublic 具有更高的 goodput,导致它可能更优秀一些)。然而在深层缓冲中,Cublic 的 goodput 增益并没有 BBR 在浅缓冲中的增益来得高,例如,在 200ms 的RTT 和 500Mbps 的带宽下,与 Cubic 相比,BBR 的吞吐量提高了 115%。这是因为 BBR 使用带宽和延迟估计作为拥塞信号而不是数据包丢失。
由于 cwnd_gain 值通常会被配置为 2,但是当缓冲区小于 BDP 的大小时候,情况就有些难看了,BBR 发现队列溢出就会启用重传机制,甚至可能比 Cublic 高出数十倍到百倍!这是因为 Cublic 达到浅缓冲的容量大小时候,第一反应是降低 cwnd,从而避免了更多不必要的损失。对于一个 100KB 的缓冲区来说,BBR 和 Cublic 平均损耗为 10.1% 与 0.9%,对于 10MB 的深缓冲区来说,BBR 和 Cublic 平均损耗率为 0.8% 和 1.3%。
以此引申另外一个指标: $$LatDec^{bbr}_{cublic} = \dfrac{latency |Cubic − latency|BBR}{latency |Cubic} * 100$$
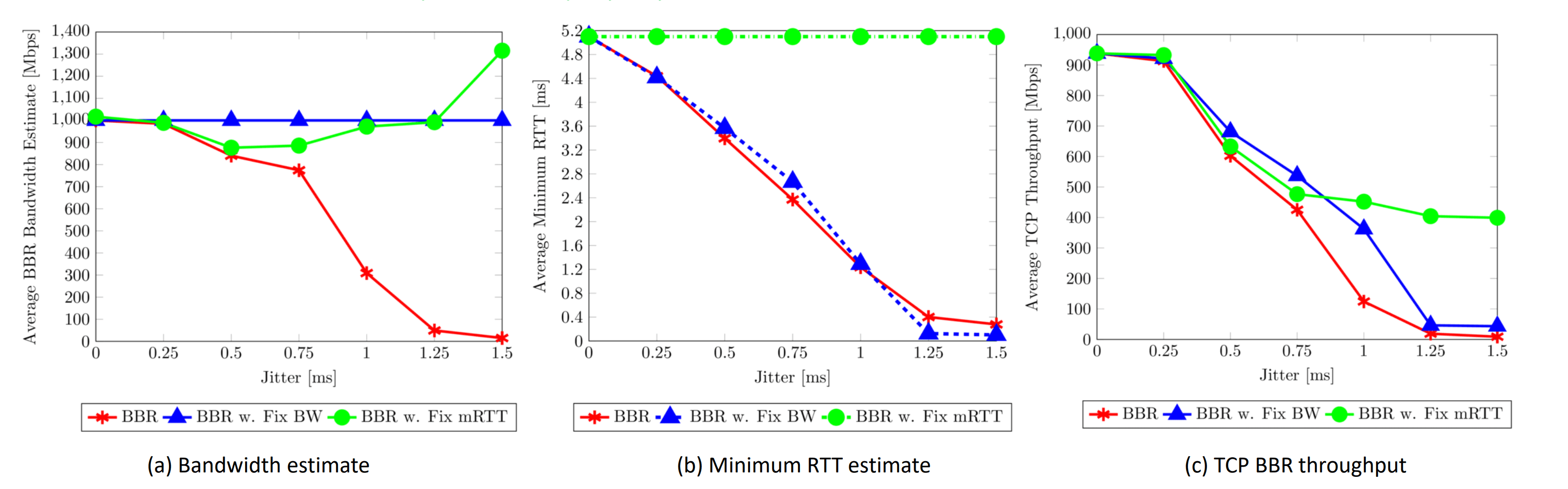
忽略丢包的缺点
还是基于上面的图进行的实验,按理说在当前的 Linux 实现中,BBR 并不会对丢包做出反应,然而我们缺观察到,当线路损耗率过高的时候(可以是出现外部因素),BBR 的 goodput 出现了突然下降,约 20% 左右,这是否就意味着,当损耗率(亦或者说是丢包率)出现了一个"临界点",而当超过这个 “临界点” 时候,BBR 会 “一不小心” 对损失作出反应。
进一步地,我们发现临界点与 pacing_gain 有着千丝万缕的关系,如果我们设丢包率为 p,而带宽探测时 BBR 的步长为
$$ pacing_gain × BW$$
加上损耗导致的无效起时速率,我们通过求解最终的表达式
$$pacing_gain × BW × (1 − p) = BW$$
可以算出,临界点为 p = 1 -1 / pacing_gain,在我们实验中,最大的 pacing_gain 为 1.25,所以异常反应的临界点应该为 p = 0.2,或者 20% 的损耗率,下图就是一张临界点损失的说明

总结改进后的代码
我们的代码改进从两个方向下手:
- 通过将带宽估计值固定为瓶颈链路容量,以用于准确计算 BDP,而其难点在于如何准确计算出链路容量
- 是否可以将最小 RTT 固定为无拥堵的平均 RTT,以便在计算估计 BDP 时使用它?
- 既然现实网络由于 Buffer 存在导致 BBR 处于天然劣势,我们是否能变得将其激进一些
关键部分代码
# 通过CWND进行快速恢复
static bool bbr_set_cwnd_to_recover_or_restore(
struct sock *sk, const struct rate_sample *rs, u32 acked, u32 *new_cwnd)
{
struct tcp_sock *tp = tcp_sk(sk);
struct bbr *bbr = inet_csk_ca(sk);
u8 prev_state = bbr->prev_ca_state, state = inet_csk(sk)->icsk_ca_state;
u32 cwnd = tp->snd_cwnd;
if (rs->losses > 0)
cwnd = max_t(s32, cwnd - rs->losses, 1);
if (state == TCP_CA_Recovery && prev_state != TCP_CA_Recovery) {
bbr->packet_conservation = 1;
bbr->next_rtt_delivered = tp->delivered;
cwnd = tcp_packets_in_flight(tp) + acked;
} else if (prev_state >= TCP_CA_Recovery && state < TCP_CA_Recovery) {
bbr->restore_cwnd = 1;
bbr->packet_conservation = 0;
}
bbr->prev_ca_state = state;
if (bbr->restore_cwnd) {
cwnd = max(cwnd, bbr->prior_cwnd);
bbr->restore_cwnd = 0;
}
if (bbr->packet_conservation) {
*new_cwnd = max(cwnd, tcp_packets_in_flight(tp) + acked);
return true;
}
*new_cwnd = cwnd;
return false;
}
# BDP 的计算
static u32 bbr_bdp(struct sock *sk, u32 bw, int gain)
{
struct bbr *bbr = inet_csk_ca(sk);
u32 bdp;
u64 w;
if (unlikely(bbr->min_rtt_us == ~0U))
return TCP_INIT_CWND;
w = (u64)bw * bbr->min_rtt_us;
bdp = (((w * gain) >> BBR_SCALE) + BW_UNIT - 1) / BW_UNIT;
return bdp;
}
# Pacing Rate的优化
static void bbr_set_pacing_rate(struct sock *sk, u32 bw, int gain)
{
struct tcp_sock *tp = tcp_sk(sk);
struct bbr *bbr = inet_csk_ca(sk);
u32 rate = bbr_bw_to_pacing_rate(sk, bw, gain);
if (unlikely(!bbr->has_seen_rtt && tp->srtt_us))
bbr_init_pacing_rate_from_rtt(sk);
if (bbr_full_bw_reached(sk) || rate > sk->sk_pacing_rate)
sk->sk_pacing_rate = rate;
}
# RTT 的计算
static void bbr_update_min_rtt(struct sock *sk, const struct rate_sample *rs)
{
struct tcp_sock *tp = tcp_sk(sk);
struct bbr *bbr = inet_csk_ca(sk);
bool filter_expired;
filter_expired = after(tcp_jiffies32,
bbr->min_rtt_stamp + bbr_min_rtt_win_sec * HZ);
if (rs->rtt_us >= 0 &&
(rs->rtt_us < bbr->min_rtt_us || filter_expired)) {
bbr->min_rtt_us = rs->rtt_us;
bbr->min_rtt_stamp = tcp_jiffies32;
}
if (bbr_probe_rtt_mode_ms > 0 && filter_expired &&
!bbr->idle_restart && bbr->mode != BBR_PROBE_RTT) {
bbr->mode = BBR_PROBE_RTT;
bbr->pacing_gain = BBR_UNIT;
bbr->cwnd_gain = BBR_UNIT;
bbr_save_cwnd(sk);
bbr->probe_rtt_done_stamp = 0;
}
if (bbr->mode == BBR_PROBE_RTT) {
tp->app_limited =
(tp->delivered + tcp_packets_in_flight(tp)) ? : 1;
if (!bbr->probe_rtt_done_stamp &&
tcp_packets_in_flight(tp) <= bbr_cwnd_min_target) {
bbr->probe_rtt_done_stamp = tcp_jiffies32
msecs_to_jiffies(bbr_probe_rtt_mode_ms);
bbr->probe_rtt_round_done = 0;
bbr->next_rtt_delivered = tp->delivered;
} else if (bbr->probe_rtt_done_stamp) {
if (bbr->round_start)
bbr->probe_rtt_round_done = 1;
if (bbr->probe_rtt_round_done &&
after(tcp_jiffies32, bbr->probe_rtt_done_stamp)) {
bbr->min_rtt_stamp = tcp_jiffies32;
bbr->restore_cwnd = 1;
bbr_reset_mode(sk);
}
}
}
if (rs->delivered > 0)
bbr->idle_restart = 0;
}
这里就把这个模块叫做 BBRMO 吧
流程
- 下载 Linux Kernel 4.14.91 版本源码
- 修改 TCP BBR 部分源码
- 重新根据内核依赖打包出修改后的模块
- 安装模块,测试效果
$ mkdir kernel && cd kernel
$ wget https://cdn.kernel.org/pub/linux/kernel/v5.x/linux-5.10.16.tar.gz
$ tar xvf linux-5.10.16.tar.gz && cd linux-5.10.16/
$ patch -p1 < linux-5.10.x_src_to_bbrmo.patch # 通过补丁包更新内核源码
patching file include/net/inet_connection_sock.h
patching file include/net/tcp.h
Hunk #1 succeeded at 571 (offset 11 lines).
Hunk #2 succeeded at 1081 (offset 7 lines).
patching file net/ipv4/Kconfig
patching file net/ipv4/Makefile
patching file net/ipv4/tcp_bbrmo.c
patching file net/ipv4/tcp_output.c
Hunk #1 succeeded at 1955 (offset -1 lines).
Hunk #2 succeeded at 1973 (offset -1 lines).
patching file net/sched/Kconfig
# 安装编译依赖
$ sudo apt install build-essential libncurses5-dev flex
$ sudo apt build-dep linux
# 编译修改后的内核
$ make oldconfig
$ cat .config | grep BBRMO
CONFIG_TCP_CONG_BBRMO=y
CONFIG_DEFAULT_BBRMO=y
$ vim .config
# 把 CONFIG_MODULE_SIG_ALL/CONFIG_MODULE_SIG_KEY/CONFIG_SYSTEM_TRUSTED_KEYS 三项注释掉,编译时系统会自动生成一次性密钥来加密
$ scripts/config --disable DEBUG_INFO && scripts/config --disable MODULE_SIG
$ make deb-pkg -j$(cat /proc/cpuinfo | grep processor | wc -l)
dpkg-deb: building package 'linux-image-5.10.16' in '../linux-image-5.10.16_5.10.16-1_amd64.deb'.
dpkg-genbuildinfo
dpkg-genchanges >../linux-5.10.16_5.10.16-1_amd64.changes
dpkg-genchanges: info: including full source code in upload
dpkg-source -i.git --after-build .
dpkg-buildpackage: info: full upload (original source is included)
$ dpkg -i *.deb # 安装 Kernel 后重启服务器即可
这时候已经能看到我们修改过的 BBRMO 协议了
$ sudo sysctl net.ipv4.tcp_available_congestion_control
net.ipv4.tcp_available_congestion_control = reno bbrmo cubic
$ sudo sysctl net.ipv4.tcp_congestion_control
net.ipv4.tcp_congestion_control = bbrmo
修改后的测试
Cublic
$ sysctl net.ipv4.tcp_congestion_control # 查看当前服务器使用什么拥塞控制算法
net.ipv4.tcp_congestion_control = cubic
# 普通不限制的正常线路
# 最大带宽 8Mbits 左右
Connecting to host 8.219.11.202, port 5201
[ 5] local 192.168.20.129 port 60962 connected to 8.219.11.202 port 5201
[ ID] Interval Transfer Bitrate Retr Cwnd
[ 5] 0.00-1.00 sec 2.12 MBytes 17.8 Mbits/sec 0 214 KBytes
[ 5] 1.00-2.00 sec 1.12 MBytes 9.44 Mbits/sec 0 214 KBytes
[ 5] 2.00-3.00 sec 1.00 MBytes 8.39 Mbits/sec 40 94.1 KBytes
[ 5] 3.00-4.00 sec 1.12 MBytes 9.44 Mbits/sec 0 214 KBytes
[ 5] 4.00-5.00 sec 1.00 MBytes 8.39 Mbits/sec 0 198 KBytes
[ 5] 5.00-6.00 sec 1.12 MBytes 9.44 Mbits/sec 10 218 KBytes
[ 5] 6.00-7.00 sec 896 KBytes 7.34 Mbits/sec 0 214 KBytes
[ 5] 7.00-8.00 sec 896 KBytes 7.34 Mbits/sec 0 191 KBytes
[ 5] 8.00-9.00 sec 1.00 MBytes 8.39 Mbits/sec 0 217 KBytes
[ 5] 9.00-10.00 sec 896 KBytes 7.34 Mbits/sec 0 204 KBytes
[ 5] 10.00-11.00 sec 896 KBytes 7.34 Mbits/sec 22 185 KBytes
[ 5] 11.00-12.00 sec 896 KBytes 7.34 Mbits/sec 0 220 KBytes
[ 5] 12.00-13.00 sec 1.12 MBytes 9.44 Mbits/sec 21 210 KBytes
[ 5] 13.00-14.00 sec 1.12 MBytes 9.44 Mbits/sec 17 200 KBytes
[ 5] 14.00-15.00 sec 1.00 MBytes 8.39 Mbits/sec 37 173 KBytes
[ 5] 15.00-16.00 sec 1.12 MBytes 9.44 Mbits/sec 22 218 KBytes
[ 5] 16.00-17.00 sec 1.12 MBytes 9.44 Mbits/sec 0 212 KBytes
[ 5] 17.00-18.00 sec 896 KBytes 7.34 Mbits/sec 0 214 KBytes
[ 5] 18.00-19.00 sec 1.12 MBytes 9.44 Mbits/sec 0 211 KBytes
[ 5] 19.00-20.00 sec 1.00 MBytes 8.39 Mbits/sec 0 212 KBytes
[ 5] 20.00-21.00 sec 1.00 MBytes 8.39 Mbits/sec 0 113 KBytes
[ 5] 21.00-22.00 sec 896 KBytes 7.34 Mbits/sec 8 121 KBytes
[ 5] 22.00-23.00 sec 768 KBytes 6.29 Mbits/sec 6 5.70 KBytes
[ 5] 23.00-24.00 sec 1.00 MBytes 8.39 Mbits/sec 0 160 KBytes
[ 5] 24.00-25.00 sec 896 KBytes 7.34 Mbits/sec 0 52.8 KBytes
[ 5] 25.00-26.00 sec 896 KBytes 7.34 Mbits/sec 0 79.8 KBytes
[ 5] 26.00-27.00 sec 896 KBytes 7.34 Mbits/sec 2 190 KBytes
[ 5] 27.00-28.00 sec 1.00 MBytes 8.39 Mbits/sec 0 133 KBytes
[ 5] 28.00-29.00 sec 896 KBytes 7.34 Mbits/sec 0 137 KBytes
[ 5] 29.00-30.00 sec 896 KBytes 7.34 Mbits/sec 0 163 KBytes
- - - - - - - - - - - - - - - - - - - - - - - - -
[ ID] Interval Transfer Bitrate Retr
[ 5] 0.00-30.00 sec 30.4 MBytes 8.49 Mbits/sec 185 sender
[ 5] 0.00-30.07 sec 28.9 MBytes 8.06 Mbits/sec receiver
iperf Done.
# 在两台机器中间收发方向增加 100ms 的延迟
$ ping 8.219.11.202
PING 8.219.11.202 (8.219.11.202) 56(84) bytes of data.
64 bytes from 8.219.11.202: icmp_seq=1 ttl=128 time=154 ms
64 bytes from 8.219.11.202: icmp_seq=2 ttl=128 time=152 ms
# 延迟达到 150ms 后,带宽下降到了 3Mbits
[ 5] 25.00-26.00 sec 384 KBytes 3.15 Mbits/sec 0 211 KBytes
[ 5] 26.00-27.00 sec 384 KBytes 3.15 Mbits/sec 0 202 KBytes
[ 5] 27.00-28.00 sec 384 KBytes 3.15 Mbits/sec 0 163 KBytes
[ 5] 28.00-29.00 sec 384 KBytes 3.15 Mbits/sec 0 215 KBytes
[ 5] 29.00-30.00 sec 512 KBytes 4.19 Mbits/sec 26 215 KBytes
- - - - - - - - - - - - - - - - - - - - - - - - -
[ ID] Interval Transfer Bitrate Retr
[ 5] 0.00-30.00 sec 13.2 MBytes 3.70 Mbits/sec 140 sender
[ 5] 0.00-30.16 sec 11.7 MBytes 3.27 Mbits/sec receiver
# 继续引入15%的丢包率,模拟恶劣网络情况
$ tc qdisc del dev eth0 root
$ tc qdisc replace dev eth0 root netem loss 15% latency 100ms
PING 8.219.11.202 (8.219.11.202) 56(84) bytes of data.
64 bytes from 8.219.11.202: icmp_seq=1 ttl=128 time=149 ms
64 bytes from 8.219.11.202: icmp_seq=2 ttl=128 time=156 ms
--- 8.219.11.202 ping statistics ---
7 packets transmitted, 5 received, 15.5714% packet loss, time 6015ms
rtt min/avg/max/mdev = 147.618/150.953/155.996/2.855 ms
# Cublic 恶劣网络下,约>3Mits
[ 5] 28.00-29.00 sec 384 KBytes 2.15 Mbits/sec 8 167 KBytes
[ 5] 29.00-30.00 sec 384 KBytes 3.15 Mbits/sec 10 164 KBytes
- - - - - - - - - - - - - - - - - - - - - - - - -
[ ID] Interval Transfer Bitrate Retr
[ 5] 0.00-30.00 sec 13.0 MBytes 2.64 Mbits/sec 155 sender
[ 5] 0.00-30.16 sec 11.6 MBytes 2.22 Mbits/sec receiver
BBR 原版
# 50ms
[ 5] 18.00-19.00 sec 1.00 MBytes 8.39 Mbits/sec 35 106 KBytes
[ 5] 19.00-20.00 sec 1.00 MBytes 8.39 Mbits/sec 24 71.3 KBytes
[ 5] 20.00-21.00 sec 1.12 MBytes 9.44 Mbits/sec 0 104 KBytes
[ 5] 21.00-22.00 sec 1.12 MBytes 9.44 Mbits/sec 0 117 KBytes
[ 5] 22.00-23.00 sec 1.25 MBytes 10.5 Mbits/sec 21 212 KBytes
[ 5] 23.00-24.00 sec 1.12 MBytes 9.44 Mbits/sec 2 212 KBytes
[ 5] 24.00-25.00 sec 1.00 MBytes 8.39 Mbits/sec 17 211 KBytes
[ 5] 25.00-26.00 sec 1.00 MBytes 8.39 Mbits/sec 0 221 KBytes
[ 5] 26.00-27.00 sec 1.00 MBytes 8.39 Mbits/sec 44 211 KBytes
[ 5] 27.00-28.00 sec 1.25 MBytes 10.5 Mbits/sec 8 164 KBytes
[ 5] 28.00-29.00 sec 1.12 MBytes 9.44 Mbits/sec 9 218 KBytes
[ 5] 29.00-30.00 sec 1.25 MBytes 10.5 Mbits/sec 2 210 KBytes
- - - - - - - - - - - - - - - - - - - - - - - - -
[ ID] Interval Transfer Bitrate Retr
[ 5] 0.00-30.00 sec 33.1 MBytes 9.26 Mbits/sec 269 sender
[ 5] 0.00-30.06 sec 31.7 MBytes 8.84 Mbits/sec receiver
# 150ms
[ 5] 24.00-25.00 sec 384 KBytes 5.15 Mbits/sec 4 211 KBytes
[ 5] 25.00-26.00 sec 384 KBytes 3.15 Mbits/sec 27 201 KBytes
[ 5] 26.00-27.00 sec 512 KBytes 4.19 Mbits/sec 11 208 KBytes
[ 5] 27.00-28.00 sec 384 KBytes 4.15 Mbits/sec 0 178 KBytes
[ 5] 28.00-29.00 sec 384 KBytes 4.15 Mbits/sec 0 207 KBytes
[ 5] 29.00-30.00 sec 384 KBytes 4.15 Mbits/sec 25 221 KBytes
- - - - - - - - - - - - - - - - - - - - - - - - -
[ ID] Interval Transfer Bitrate Retr
[ 5] 0.00-30.00 sec 13.5 MBytes 4.77 Mbits/sec 229 sender
[ 5] 0.00-30.16 sec 12.1 MBytes 4.35 Mbits/sec receiver
# 150ms + 15% loss
[ 5] 26.00-27.00 sec 384 KBytes 3.15 Mbits/sec 14 71.3 KBytes
[ 5] 27.00-28.00 sec 512 KBytes 4.19 Mbits/sec 7 78.4 KBytes
[ 5] 28.00-29.00 sec 384 KBytes 3.15 Mbits/sec 0 103 KBytes
[ 5] 29.00-30.00 sec 384 KBytes 3.15 Mbits/sec 0 128 KBytes
- - - - - - - - - - - - - - - - - - - - - - - - -
[ ID] Interval Transfer Bitrate Retr
[ 5] 0.00-30.00 sec 13.6 MBytes 3.81 Mbits/sec 59 sender
[ 5] 0.00-31.05 sec 12.2 MBytes 3.29 Mbits/sec receiver
BBR 修改后
$ uname -a
Linux iZt4n9q1doqvd6zdgmhuypZ 5.10.16 #1 SMP Wed Mar 30 09:34:58 CDT 2022 x86_64 GNU/Linux
# 带宽居然达到了11MB/s
[ 5] 26.00-27.00 sec 1.38 MBytes 11.5 Mbits/sec 0 103 KBytes
[ 5] 27.00-28.00 sec 1.50 MBytes 12.6 Mbits/sec 0 68.4 KBytes
[ 5] 28.00-29.00 sec 1.50 MBytes 12.6 Mbits/sec 0 85.5 KBytes
[ 5] 29.00-30.00 sec 1.38 MBytes 11.5 Mbits/sec 0 98.4 KBytes
- - - - - - - - - - - - - - - - - - - - - - - - -
[ ID] Interval Transfer Bitrate Retr
[ 5] 0.00-30.00 sec 43.5 MBytes 12.2 Mbits/sec 127 sender
[ 5] 0.00-30.05 sec 42.1 MBytes 11.8 Mbits/sec receiver
# 150ms
[ 5] 26.00-27.00 sec 512 KBytes 4.20 Mbits/sec 0 197 KBytes
[ 5] 27.00-28.00 sec 384 KBytes 3.15 Mbits/sec 0 120 KBytes
[ 5] 28.00-29.00 sec 384 KBytes 3.15 Mbits/sec 0 104 KBytes
[ 5] 29.00-30.00 sec 512 KBytes 4.19 Mbits/sec 0 95.5 KBytes
- - - - - - - - - - - - - - - - - - - - - - - - -
[ ID] Interval Transfer Bitrate Retr
[ 5] 0.00-30.00 sec 13.9 MBytes 3.88 Mbits/sec 36 sender
[ 5] 0.00-30.15 sec 12.4 MBytes 3.46 Mbits/sec receiver
# 15% loss
[ 5] 27.00-28.00 sec 512 KBytes 4.20 Mbits/sec 0 210 KBytes
[ 5] 28.00-29.00 sec 384 KBytes 3.15 Mbits/sec 0 128 KBytes
[ 5] 29.00-30.00 sec 512 KBytes 4.19 Mbits/sec 0 194 KBytes
- - - - - - - - - - - - - - - - - - - - - - - - -
[ ID] Interval Transfer Bitrate Retr
[ 5] 0.00-30.00 sec 14.1 MBytes 4.01 Mbits/sec 105 sender
[ 5] 0.00-30.15 sec 12.6 MBytes 3.51 Mbits/sec receiver
结果已经出来了
| name | 50ms | 150ms | 150ms+15%loss |
|---|---|---|---|
| Cublic | 8.5MB/s | 3.7MB/s | 2.6MB/s |
| BBRv1 | 9.2MB/s | 4.7MB/s | 3.8MB/s |
| BBRMO | 12.2MB/s | 3.8MB/s | 4.1MB/s |
Patch 补丁包代码 linux-5.10.x_src_to_bbrmo.patch
参考
下面是重点参考的书籍与文章,包括引用了图片等内容
- 《Linux内核源码剖析:TCP/IP实现》 - 机械工业出版社
- 《Web协议详解与抓包实战》- 极客时间课程
- 《BBRCongestion-Based Congestion Control》
- 《RFC2581》 - RFC TCP 拥塞控制公开标准文档
- 《拥塞窗口cwnd的理解》 - xuanspace CSDN 博客
- 《Making Linux TCP Fast》 - Google Paper
- 《TCP拥塞控制之ABC》 - Switch-Router
- 《TCP Reno and Congestion Management》- Loyola University Chicago
- 《TCP BBR for Ultra-Low Latency Networking: Challenges, Analysis, and Solutions》- Rajeev Kumar
- 《When to use and when not to use BBR: An empirical analysisand evaluation study》 - Yi Cao Stony Brook University